Datasets
- CVPR 2023: 5th Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW)
- ECCV 2022: 4th Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW)
- CVPR 2022: 3rd Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW)
- ICCV 2021: 2nd Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW)
- Synthesizing Coupled 3D Face Modalities by TBGAN
- Face Bio-metrics under COVID (Masked Face Recognition Challenge & Workshop ICCV 2021)
- First Affect-in-the-Wild Challenge
- Aff-Wild2 database
- FG-2020 Competition: Affective Behavior Analysis in-the-wild (ABAW)
- First Faces in-the-wild Workshop-Challenge
- In-The-Wild 3D Morphable Models: Code and Data
- Sound of Pixels
- Lightweight Face Recognition Challenge & Workshop (ICCV 2019)
- Audiovisual Database of Normal-Whispered-Silent Speech
- Deformable Models of Ears in-the-wild for Alignment and Recognition
- 300 Videos in the Wild (300-VW) Challenge & Workshop (ICCV 2015)
- 1st 3D Face Tracking in-the-wild Competition
- The Fabrics Dataset
- The Mobiface Dataset
- Large Scale Facial Model (LSFM)
- AgeDB
- AFEW-VA Database for Valence and Arousal Estimation In-The-Wild
- The CONFER Database
- Special Issue on Behavior Analysis "in-the-wild"
- Body Pose Annotations Correction (CVPR 2016)
- KANFace
- MeDigital
- FG-2020 Workshop "Affect Recognition in-the-wild: Uni/Multi-Modal Analysis & VA-AU-Expression Challenges"
- 4DFAB: A Large Scale 4D Face Database for Expression Analysis and Biometric Applications
- Affect "in-the-wild" Workshop
- 2nd Facial Landmark Localisation Competition - The Menpo BenchMark
- Facial Expression Recognition and Analysis Challenge 2015
- The SEWA Database
- Mimic Me
- 300 Faces In-The-Wild Challenge (300-W), IMAVIS 2014
- MAHNOB-HCI-Tagging database
- 300 Faces In-the-Wild Challenge (300-W), ICCV 2013
- MAHNOB Laughter database
- MAHNOB MHI-Mimicry database
- Facial point annotations
- MMI Facial expression database
- SEMAINE database
- iBugMask: Face Parsing in the Wild (ImaVis 2021)
- iBUG Eye Segmentation Dataset
Code
- Valence/Arousal Online Annotation Tool
- The Menpo Project
- The Dynamic Ordinal Classification (DOC) Toolbox
- Gauss-Newton Deformable Part Models for Face Alignment in-the-Wild (CVPR 2014)
- Robust and Efficient Parametric Face/Object Alignment (2011)
- Discriminative Response Map Fitting (DRMF 2013)
- End-to-End Lipreading
- DS-GPLVM (TIP 2015)
- Subspace Learning from Image Gradient Orientations (2011)
- Discriminant Incoherent Component Analysis (IEEE-TIP 2016)
- AOMs Generic Face Alignment (2012)
- Fitting AAMs in-the-Wild (ICCV 2013)
- Salient Point Detector (2006/2008)
- Facial point detector (2010/2013)
- Chehra Face Tracker (CVPR 2014)
- Empirical Analysis Of Cascade Deformable Models For Multi-View Face Detection (IMAVIS 2015)
- Continuous-time Prediction of Dimensional Behavior/Affect
- Real-time Face tracking with CUDA (MMSys 2014)
- Facial Point detector (2005/2007)
- Facial tracker (2011)
- Salient Point Detector (2010)
- AU detector (TAUD 2011)
- Action Unit Detector (2016)
- AU detector (LAUD 2010)
- Smile Detectors
- Head Nod Shake Detector (2010/2011)
- Gesture Detector (2011)
- Head Nod Shake Detector and 5 Dimensional Emotion Predictor (2010/2011)
- Gesture Detector (2010)
- HCI^2 Framework
- FROG Facial Tracking Component
- SEMAINE Visual Components (2008/2009)
- SEMAINE Visual Components (2009/2010)
Deformable Models of Ears in-the-wild for Alignment and Recognition
Introduction
Given the increasing focus on automatic identity verification during the last decade, biometrics have attracted extended attention. Such applications seek of biometric characteristics that are special, common and quantifiable. One such biometric is human ear [12], [13]. The human outer ear consists of the following parts: outer helix, antihelix, lobe, tragus, antitragus, helicis, crus helicis and concha (see Figure 2). The inner structure of the human ear is formed with numerous rides and valleys which makes it very distinctive. Even though the human ear’s structure is not completely random, it still brings significant differences between individuals. The influence of randomness on appearance can be observed even by comparing both ears of the same person. Ears of same person have similarities but still are not perfectly symmetric [30].
The complex interior shape of ears has long been considered as a valuable identification metric. The first time it was utilised for human verification was hundreds years ago [10]. Several years later, researchers demonstrated that 500 ears can be distinguished using only four features [24]. The work of [23] also showed that 10k ears can be determined with 12 features. Furthermore, ear can be in many cases combined with face for improved person recognition and verification [12].
As in many biometrics, such as face [36], the first step towards recognition/verification is, arguably, alignment. Since, ear is a deformable object a statistical deformable model should be learned. In order to learn the first statistical deformable model of the ear we collected and annotated, with regards to 55 landmarks, the first ”in-the-wild” ear database. Furthermore, we conducted an extensive experimental comparison for ear landmark localisation using state-of-the-art generative and discriminative methodologies for training and fitting statistical deformable models [15], [14], [28], [33], [8], [40], [11], [6], [37], [7], [5]. Figure 1 visualises the mean and the first variations along the 5 principal components of the texture and the shape (as performed in Active Appearance Model [14], [28], [37], [5]).
The other contribution of the paper is the collection of a new ”in-the-wild” database suitable for ear verification and recognition. The collected database consists of 231 subjects with 2058 ”in-the-wild” images. We conduct extensive experimental comparisons in the newly collected database using various handcrafted features such as Image Gradient Orientation (IGO) [38], Scale Invariant Feature Transforms (SIFT) [27], Histogram of Oriented Gradients (HOG) [17], as well as learned deep convolutional features [34]. Finally, we compare the effect of alignment in ear recognition/verification.
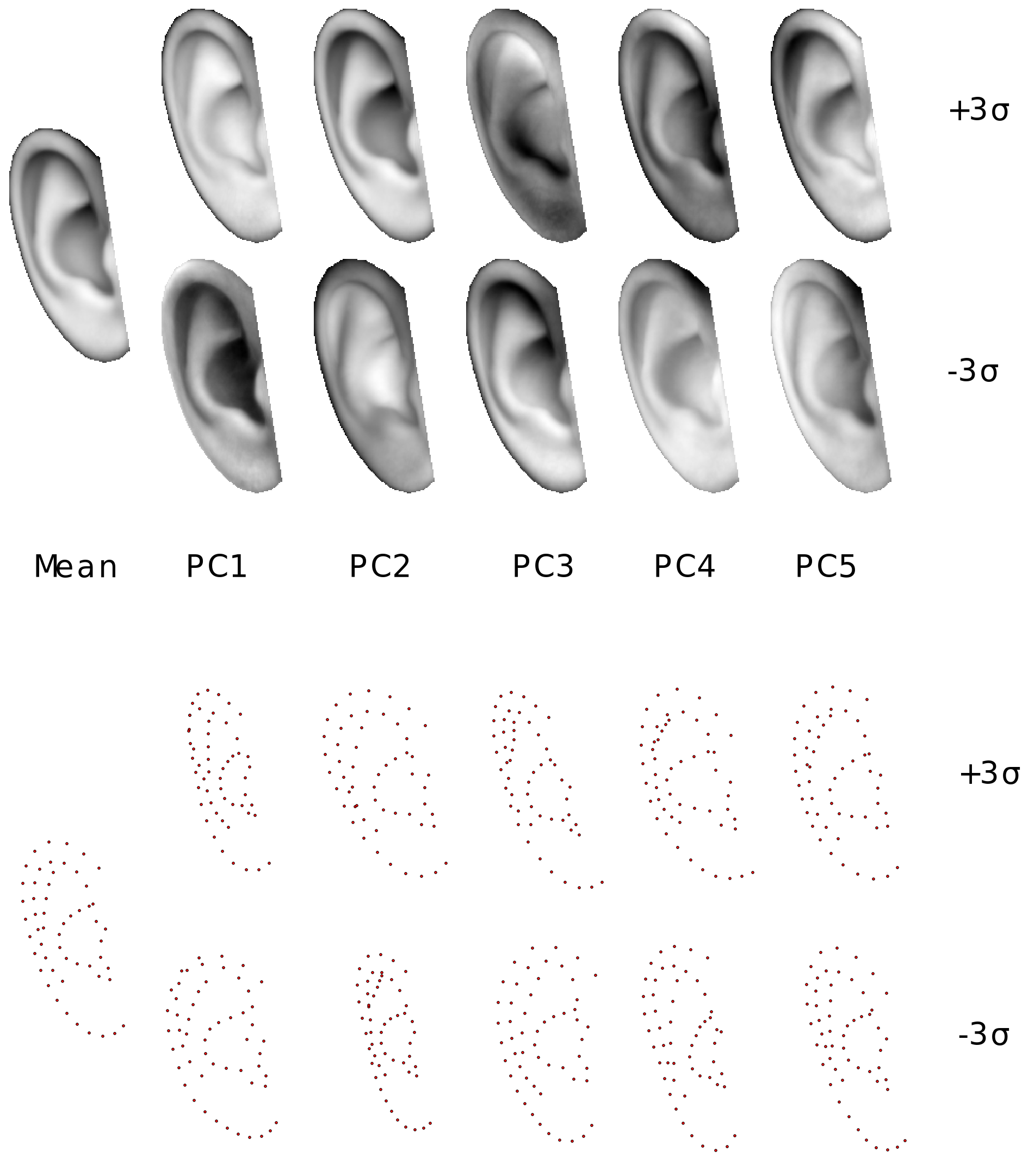
Fig. 1. Exemplar statistical shape and appearance model of human ear. The figure visualises the first five principal components variation in both models. Appearance model is created with pixel intensity for better visualisation.
“In-the-wild” Ear Database
We collected two sets of ear images “in-the-wild”. The first was used for statistical deformable model construction (Collection A), while the latter was used for ear verification and recognition “in-the-wild” (Collection B).
Collection A consists of 605 ear images “in-the-wild” collected from Google Images with no specific identity (by searching using the ear related tags). Each is manually annotated with 55 landmark points. Examples of such annotated images and the anatomy of pinna is shown in figure 2. The semantic meaning of the 55 landmarks are: ascending helix (0-3), descending helix (4-7), helix (8-13), ear lobe (14-19), ascending inner helix (20-24), descending inner helix (25- 28), inner helix (29-34), tragus (35-38), canal (39), antitragus (40-42), concha (43-46), inferio crus (47-49) and supperio crus (50-54). We randomly split the images into two disjoint sets for training (500) and testing (105). The purpose of Collection A is to build statistical deformable models with unconstrained ear samples.
Collection B contains 2058 images contains 231 identitylabelled subjects collected from VGG database [29], which contains more than one million images of celebrities with only identity labels. As the purpose of VGG database was face recognition ”in-the-wild”, we had to manual select images were ears are visible (not fully occluded) and furthermore there bounding box could be generated by a simple HoG Support Vector Machine (SVM) [17] ear detector (trained on collection A). Exemplar collected ear images are shown in Figure 2 that images are under challenging environment such as heavily posed angel, significant lighting variations, notable occlusions, variant resolutions, and significant ageing. It is so far, to the best of out knowledge, the largest ear in-the-wild databases.
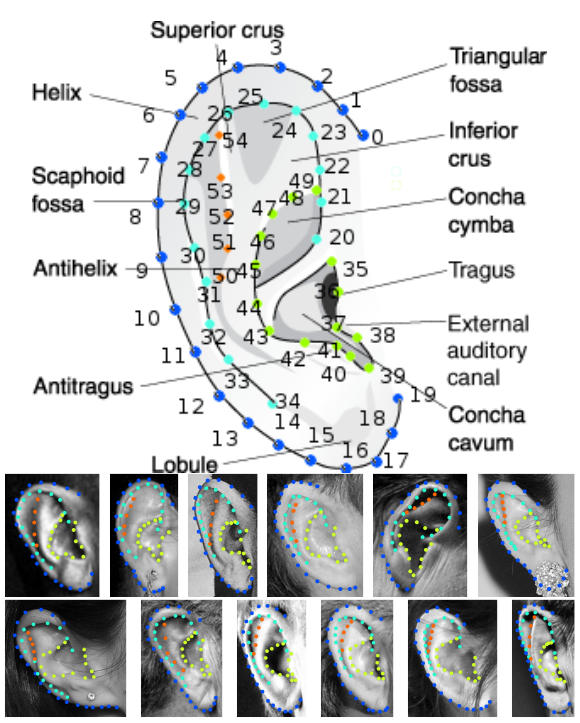
Fig. 2. Example of the annotated 55 landmarks on ears. Ascending helix (0- 3), descending helix (4-7), helix (8-13), ear lobe (14-19), ascending inner helix (20-24), descending inner helix (25-28), inner helix (29-34), tragus (35-38), canal (39), antitragus (40-42), concha (43-46), inferio crus (47-49) and supperio crus (50-54).
Downloads
Ear "in-the-wild" datasets for both deformable models (Collection A) and verification/recognition (Collection B) can be found below. The data contain the ear images and their corresponding annotation (.pts file).
- The dataset is available for non-commercial research purposes only.
- All the training images of the dataset are obtained from the VGG Face, LFW, as well as from Helen databases (please cite the corresponding papers when you are using them). We are not responsible for the content nor the meaning of these images.
- You agree not to reproduce, duplicate, copy, sell, trade, resell or exploit for any commercial purposes, any portion of the annotations and any portion of derived data.
- You agree not to further copy, publish or distribute any portion of annotations of the dataset. Except, for internal use at a single site within the same organization it is allowed to make copies of the dataset.
- We reserve the right to terminate your access to the dataset at any time.
Experiments & Evaluation
Ear Fitting Evaluation
We evaluated the performance of many state-of-the-art methodologies including AAM, CLM and SDM using various kind of features. In particular, we employed pixel intensity (PI), dense SIFT (DSIFT) [27], dense HOG [17], IGO [38] and DCNN [34] features for both holistic and patch-based AAMs. The models were trained on a 3-level Gaussian pyramid. We kept [3,6,12] shape components for each level (low to high) and 90% of the appearance variance for all levels. Also discriminative models like Supervised Descend Method (SDM) [39] and Constrained Local Model (CLM) [16] are involved using features DSIFT [27].
Figure 3 reports the CED curves of all the tested methods along with the initialisation curve. The fitting is initialised using our own in-house ear detector based on HoG SVMs that was trained with in-the-wild ear images of the training set of Collection A. The figure reveals that DSIFT tends to give most representative features for ears and holistic AAMs in general outperform patch-based AAM. This is attributed to the fact that holistic texture model can represent the complex inner structure of ears in a better fashion. The poor performance of SDM could be associated to the limited annotated data, as well as to the use of a part-based texture model.
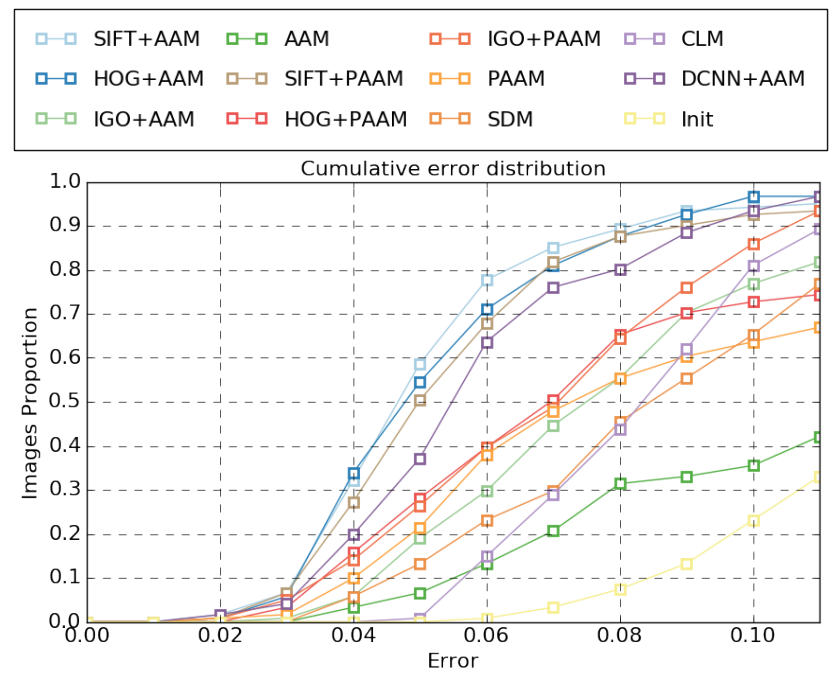
Fig. 3. Experimental results on our testing 121 dataset evaluated on 55 landmarks. Fitting accuracy reported for Holistic AAM, patch-based AAM, SDM and CLM.
Ear Recognition Experiments
In order to conduct close ear recognition experiments we conducted a 10 fold cross validation experiment where 90% were used for training and 10% testing in each fold. We report average accuracy and standard deviation. In order to compare how challenging each database is we applied the above protocol to both our database, as well as WPUTEDB, which contains largest amount of subjects and most significant appearance variance among existing ear databases but still collected under controlled environment.
From the results reported in Table 1 we can deduce the following (a) the collected database is far more challenging than the WPUTEDB, (b) the background around the ear does not play any role in the proposed database, while the background gives a 57% recognition rate in WPUTEDB, (c) the alignment largely improves performance (approximately 5% average in WPUTEDB and 10% to 20% in our database) and (d) the best performance is achieved by PPSIFT features.
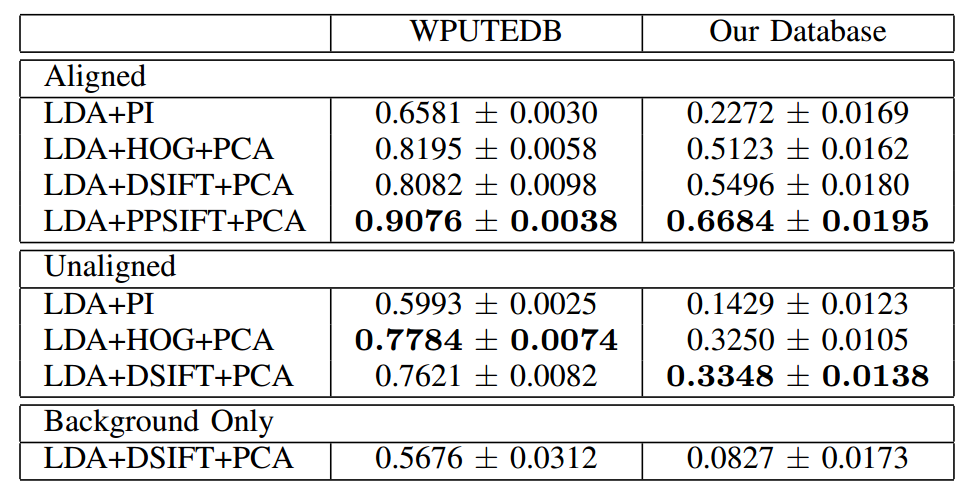
Table 1. Ear recognition experiments on WPUTEDB and the proposed database. Multiple Features and classification algorithms are applied with/without alignment.
Ear Verification Experiments
In this section we have designed and executed an ear veri- fication experiment reminiscent of the experimental protocol of Labelled Faces in-the-wild (LFW) [22]. That is, evaluation is performed by determining whether a pair of images come from the same person or not. In the case of ear verification, 185 positive and 185 negative matching pairs are generated for each fold and total five folds are generated, from which we perform a leave-one-out cross validation.
We used similar features as in the recognition experiments. In particular, we applied pixel intensities (PI), DSIFT and Deep Convolutional Neural Networks (DCNN) [35] (for DCNN we used the pre-trained VGG-16 architecture). High dimensional features, such as DSIFT, were combined with PCA for dimensionality reduction. For each pair of the training images and for each feature we computed the squared distance and formed a vector which was fed to a two class LDA or SVM which separate match versus not-match pairs. We apply the above methods to both aligned and non-aligned ear samples. Finally, we also applied the methodology that was proposed in [26] (so-called Eigen-Pep).
Overall performance over five folds is reported using mean accuracy (as in LFW). Experiments are performed under the image-restricted setting, where only binary positive or negative labels are given, for pairs of images. So the identity information of each image is not available under this setting and results are reported with both no outside training data and label-free outside data for alignment. Table 2 summarises the results. The top performance is around 68% using DCNN features and aligned images. As in the recognition experiments alignment always improves performance. Finally, Figure 4 plots the ROC curves for the tested methods.
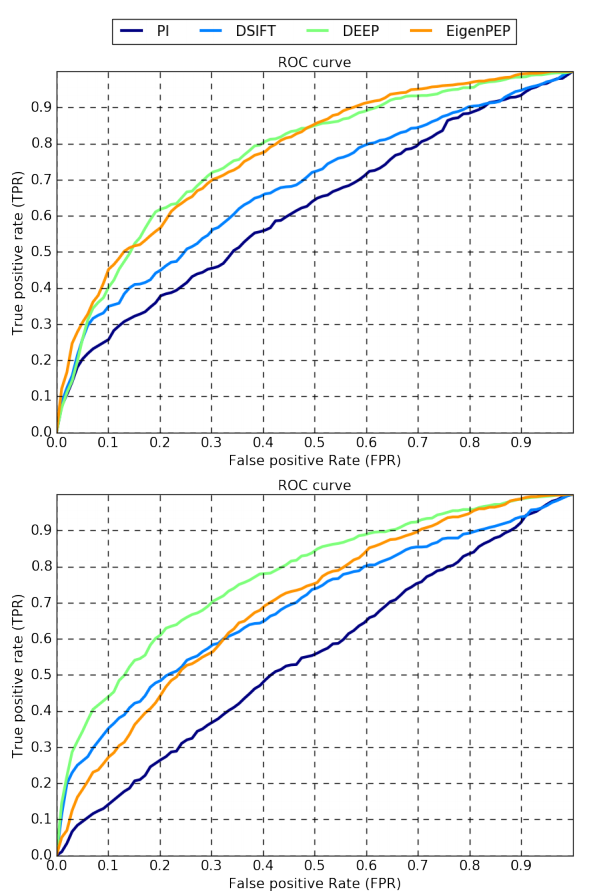
Fig. 4. ROC curves averaged over 5 folds on the proposed database (top: using aligned images, bottom: using unaligned images).
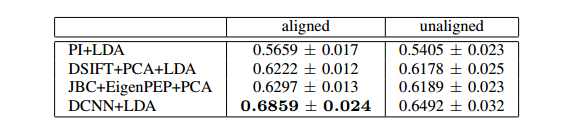
Table 2. Ear verification benchmark on the proposed database using the proposed methods.
Contributions
- We present the first annotated ”in-the-wild” database of images of ears (605 images in total) with regards to 55 landmarks. We provide the database publicly available.
- We conduct an extensive comparison between various discriminant and generative methodologies for ear landmark localisation ”in-the-wild”.
- We collect a large database of ears ”in-the-wild” for ear recognition/verification and we conduct an extensive experimental comparison.
For detailed information please refer to paper here.
References
[1] Und biometric dataset collection e, https://sites.google.com/a/nd.edu/public-cvrl/data-sets.
[2] J Alabort-i Medina, E Antonakos, J Booth, P Snape, and S Zafeiriou. Menpo: A comprehensive platform for parametric image alignment and visual deformable models. In Proceedings of the ACM International Conference on Multimedia, pages 679–682. ACM, 2014.
[3] B. Amberg, A. Blake, and T. Vetter. On compositional image alignment, with an application to active appearance models. In Conference on Computer Vision and Pattern Recognition (CVPR), 2009.
[4] R Anderson, B Stenger, and R Cipolla. Using bounded diameter minimum spanning trees to build dense active appearance models. International Journal of Computer Vision, 110(1):48–57, 2014.
[5] E. Antonakos, J. Alabort i medina, G. Tzimiropoulos, and S. Zafeiriou. Feature-based lucas-kanade and active appearance models. IEEE Transactions on Image Processing, 24(9):2617–2632, 2015.
[6] A. Asthana, S. Zafeiriou, S. Cheng, and M. Pantic. Robust discriminative response map fitting with constrained local models. In Conference on Computer Vision and Pattern Recognition (CVPR), 2013.
[7] A Asthana, S Zafeiriou, S Cheng, and M Pantic. Incremental face alignment in the wild. In Conf. on Computer Vision and Pattern Recognition (CVPR), 2014.
[8] P. N. Belhumeur, D. W. Jacobs, D. J. Kriegman, and N. Kumar. Localizing parts of faces using a consensus of exemplars. In Conference on Computer Vision and Pattern Recognition (CVPR), 2011.
[9] Peter N. Belhumeur, Joao P Hespanha, and David J. Kriegman. ˜ Eigenfaces vs. fisherfaces: Recognition using class specific linear projection. IEEE Transactions on pattern analysis and machine intelligence, 19(7):711–720, 1997.
[10] Alphonse Bertillon. La photographie judiciaire: avec un appendice sur la classification et l’identification anthropometriques ´ . GauthierVillars, 1890.
[11] Xudong Cao, Yichen Wei, Fang Wen, and Jian Sun. Face alignment by explicit shape regression. In Computer Vision and Pattern Recognition (CVPR), 2012.
[12] Kyong Chang, Kevin W Bowyer, Sudeep Sarkar, and Barnabas Victor. Comparison and combination of ear and face images in appearancebased biometrics. IEEE Transactions on pattern analysis and machine intelligence, 25(9):1160–1165, 2003.
[13] Hui Chen and Bir Bhanu. Human ear recognition in 3d. IEEE Transactions on Pattern Analysis and Machine Intelligence, 29(4):718–737, 2007.
[14] T. F. Cootes, G. J. Edwards, and C. J. Taylor. Active appearance models. Transactions on Pattern Analysis and Machine Intelligence (TPAMI), 2001.
[15] T. F. Cootes, C. J. Taylor, D. H. Cooper, and J. Graham. Active shape models: Their training and application. Computer Vision and Image Understanding, 1995.
[16] David Cristinacce and Timothy F Cootes. Feature detection and tracking with constrained local models. In BMVC, volume 1, page 3, 2006.
[17] N. Dalal and B. Triggs. Histograms of oriented gradients for human detection. In Conference on Computer Vision and Pattern Recognition (CVPR), 2005.
[18] Ziga Emer ˇ siˇ c and Peter Peer. Ear biometric database in the wild. ˇ In Bioinspired Intelligence (IWOBI), 2015 4th International Work Conference on, pages 27–32. IEEE, 2015.
[19] Dariusz Frejlichowski and Natalia Tyszkiewicz. The west pomeranian university of technology ear database–a tool for testing biometric algorithms. In Image analysis and recognition, pages 227–234. Springer, 2010.
[20] M Grgic, K Delac, and S Grgic. Scface–surveillance cameras face database. Multimedia tools and applications, 51(3):863–879, 2011.
[21] Chih-Wei Hsu and Chih-Jen Lin. A comparison of methods for multiclass support vector machines. IEEE transactions on Neural Networks, 13(2):415–425, 2002.
[22] Gary B. Huang, Manu Ramesh, Tamara Berg, and Erik Learned-Miller. Labeled faces in the wild: A database for studying face recognition in unconstrained environments. Technical Report 07-49, University of Massachusetts, Amherst, October 2007.
[23] Alfred Victor Iannarelli. Ear identification. Paramont Publishing Company, 1989.
[24] R Imhofer. Die bedeutung der ohrmuschel fur die feststellung der ¨ identitat. ¨ Archiv fur die Kriminologie ¨ , 26(150-163):3, 1906.
[25] Ajay Kumar and Chenye Wu. Automated human identification using ear imaging. Pattern Recognition, 45(3):956–968, 2012.
[26] Haoxiang Li, Gang Hua, Xiaohui Shen, Zhe Lin, and Jonathan Brandt. Eigen-pep for video face recognition. In Asian Conference on Computer Vision, pages 17–33. Springer, 2014.
[27] David G Lowe. Object recognition from local scale-invariant features. In Computer vision, 1999. The proceedings of the seventh IEEE international conference on, volume 2, pages 1150–1157. Ieee, 1999.
[28] Iain Matthews and Simon Baker. Active appearance models revisited. International Journal of Computer Vision (IJCV), 2004.
[29] O. M. Parkhi, A. Vedaldi, and A. Zisserman. Deep face recognition. In British Machine Vision Conference, 2015.
[30] A Pflug and C Busch. Ear biometrics: a survey of detection, feature extraction and recognition methods. Biometrics, IET, 1(2):114–129, 2012.
[31] K Ramnath, S Baker, I Matthews, and D Raman. Increasing the density of active appearance models. In Computer Vision and Pattern Recognition, 2008. CVPR 2008. IEEE Conference on, pages 1–8. IEEE, 2008.
[32] R Raposo, E Hoyle, A Peixinho, and H Proenc¸a. Ubear: A dataset of ear images captured on-the-move in uncontrolled conditions. In Computational Intelligence in Biometrics and Identity Management (CIBIM), 2011 IEEE Workshop on, pages 84–90. IEEE, 2011.
[33] J Saragih, S Lucey, and J Cohn. Deformable model fitting by regularized landmark mean-shift. International Journal of Computer Vision (IJCV), 2011.
[34] P Sermanet, D Eigen, X Zhang, M Mathieu, R Fergus, and Y LeCun. Overfeat: Integrated recognition, localization and detection using convolutional networks. arXiv preprint arXiv:1312.6229, 2013.
[35] Karen Simonyan and Andrew Zisserman. Very deep convolutional networks for large-scale image recognition. arXiv preprint arXiv:1409.1556, 2014.
[36] Yaniv Taigman, Ming Yang, Marc’Aurelio Ranzato, and Lior Wolf. Deepface: Closing the gap to human-level performance in face veri- fication. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 1701–1708, 2014.
[37] Georgios Tzimiropoulos and Maja Pantic. Gauss-newton deformable part models for face alignment in-the-wild. In Conference on Computer Vision and Pattern Recognition (CVPR), 2014.
[38] Georgios Tzimiropoulos, Stefanos Zafeiriou, and Maja Pantic. Subspace learning from image gradient orientations. IEEE transactions on pattern analysis and machine intelligence, 34(12):2454–2466, 2012.
[39] Xuehan Xiong and Fernando De la Torre. Supervised descent method and its applications to face alignment. In Proceedings of the IEEE conference on computer vision and pattern recognition, pages 532– 539, 2013.
[40] X Zhu and D Ramanan. Face detection, pose estimation, and landmark localization in the wild. In Conf. on Computer Vision and Pattern Recognition, 2012.