Datasets
- CVPR 2023: 5th Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW)
- ECCV 2022: 4th Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW)
- CVPR 2022: 3rd Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW)
- ICCV 2021: 2nd Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW)
- Synthesizing Coupled 3D Face Modalities by TBGAN
- Face Bio-metrics under COVID (Masked Face Recognition Challenge & Workshop ICCV 2021)
- First Affect-in-the-Wild Challenge
- Aff-Wild2 database
- FG-2020 Competition: Affective Behavior Analysis in-the-wild (ABAW)
- First Faces in-the-wild Workshop-Challenge
- In-The-Wild 3D Morphable Models: Code and Data
- Sound of Pixels
- Lightweight Face Recognition Challenge & Workshop (ICCV 2019)
- Audiovisual Database of Normal-Whispered-Silent Speech
- Deformable Models of Ears in-the-wild for Alignment and Recognition
- 300 Videos in the Wild (300-VW) Challenge & Workshop (ICCV 2015)
- 1st 3D Face Tracking in-the-wild Competition
- The Fabrics Dataset
- The Mobiface Dataset
- Large Scale Facial Model (LSFM)
- AgeDB
- AFEW-VA Database for Valence and Arousal Estimation In-The-Wild
- The CONFER Database
- Special Issue on Behavior Analysis "in-the-wild"
- Body Pose Annotations Correction (CVPR 2016)
- KANFace
- MeDigital
- FG-2020 Workshop "Affect Recognition in-the-wild: Uni/Multi-Modal Analysis & VA-AU-Expression Challenges"
- 4DFAB: A Large Scale 4D Face Database for Expression Analysis and Biometric Applications
- Affect "in-the-wild" Workshop
- 2nd Facial Landmark Localisation Competition - The Menpo BenchMark
- Facial Expression Recognition and Analysis Challenge 2015
- The SEWA Database
- Mimic Me
- 300 Faces In-The-Wild Challenge (300-W), IMAVIS 2014
- MAHNOB-HCI-Tagging database
- 300 Faces In-the-Wild Challenge (300-W), ICCV 2013
- MAHNOB Laughter database
- MAHNOB MHI-Mimicry database
- Facial point annotations
- MMI Facial expression database
- SEMAINE database
- iBugMask: Face Parsing in the Wild (ImaVis 2021)
- iBUG Eye Segmentation Dataset
Code
- Valence/Arousal Online Annotation Tool
- The Menpo Project
- The Dynamic Ordinal Classification (DOC) Toolbox
- Gauss-Newton Deformable Part Models for Face Alignment in-the-Wild (CVPR 2014)
- Robust and Efficient Parametric Face/Object Alignment (2011)
- Discriminative Response Map Fitting (DRMF 2013)
- End-to-End Lipreading
- DS-GPLVM (TIP 2015)
- Subspace Learning from Image Gradient Orientations (2011)
- Discriminant Incoherent Component Analysis (IEEE-TIP 2016)
- AOMs Generic Face Alignment (2012)
- Fitting AAMs in-the-Wild (ICCV 2013)
- Salient Point Detector (2006/2008)
- Facial point detector (2010/2013)
- Chehra Face Tracker (CVPR 2014)
- Empirical Analysis Of Cascade Deformable Models For Multi-View Face Detection (IMAVIS 2015)
- Continuous-time Prediction of Dimensional Behavior/Affect
- Real-time Face tracking with CUDA (MMSys 2014)
- Facial Point detector (2005/2007)
- Facial tracker (2011)
- Salient Point Detector (2010)
- AU detector (TAUD 2011)
- Action Unit Detector (2016)
- AU detector (LAUD 2010)
- Smile Detectors
- Head Nod Shake Detector (2010/2011)
- Gesture Detector (2011)
- Head Nod Shake Detector and 5 Dimensional Emotion Predictor (2010/2011)
- Gesture Detector (2010)
- HCI^2 Framework
- FROG Facial Tracking Component
- SEMAINE Visual Components (2008/2009)
- SEMAINE Visual Components (2009/2010)
Body Pose Annotations Correction (CVPR 2016)
Introduction
During the past few years we have witnessed the development of many methodologies for building and fitting Statistical Deformable Models (SDMs). The construction of accurate SDMs requires careful annotation of images with regards to a consistent set of landmarks. However, the manual annotation of a large amount of images is a tedious, laborious and expensive procedure. Furthermore, for several deformable objects, e.g. human body, it is difficult to define a consistent set of landmarks, and, thus, it becomes impossible to train humans in order to accurately annotate a collection of images. Nevertheless, for the majority of objects, it is possible to extract the shape by object segmentation or even by shape drawing.
We show for the first time, to the best of our knowledge, that it is possible to construct SDMs by putting object shapes in dense correspondence. Such SDMs can be built with much less effort for a large battery of objects. Additionally, we show that, by sampling the dense model, a part-based SDM can be learned with its parts being in correspondence. We employ our framework to develop SDMs of human arms and legs, which can be used for the segmentation of the outline of the human body, as well as to provide better and more consistent annotations for body joints.
Downloads
Annotation Corrections for FLIC and MPII can be found below:
Method
In order to build dense correspondences between different shape instances of the same object class, we jointly estimate the optical flow among all the instances by imposing low-rank constrains, an approach that we call Shape Flow. Multiframe optical flow has originally been applied on video sequences, relying on the assumptions of colour consistency and motion smoothness. However, these assumptions do not hold in our case, where we have a collection of shapes. Therefore, we introduce appropriate modifications based on the consistency of image-based shape representation, as well as low-rank priors.
Additionally, we show that the proposed methodology can be applied on landmark localisation, even though it is not tailored for that task, achieving particularly good performance.
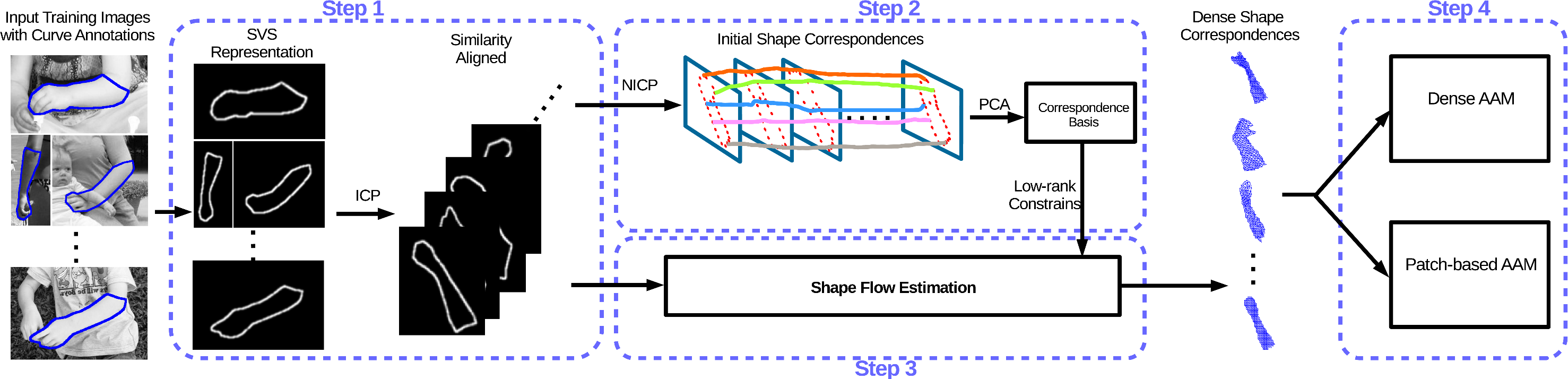
Figure 1: Schematic description of the proposed shapeflow pipeline.
Experiments & Evaluation
Pose Estimation
In this experiment, we aim to compare the effect of training a deformable model of human arm using: (i) our proposed outline sparse landmarks, and (ii) the standard skeleton joints annotations that are commonly employed in literature. For this purpose, we employ the patch-based AAM trained on outline landmarks. Additionally, we compare our methodology with the current state-of-the-art.
Dataset & Error Metric We opted to report quantitative results on the BBC Pose database [10], which provides the most consistent and accurate joints annotations compared to the rest of existing databases. The training of the outline patch-based AAM was performed after obtaining 29 outline landmarks using our proposed framework. We used 891 training images from a combination of datasets, including H3D [12], Microsoft COCO [11], MPII [7], Fashion Pose [8], FLIC [9] and BBC Pose [10]. SIFT features [12] are adopted for the image representation in our model. The fitting procedure on the BBC Pose database is initialised using a simplistic in-house deep convolutional neural network.
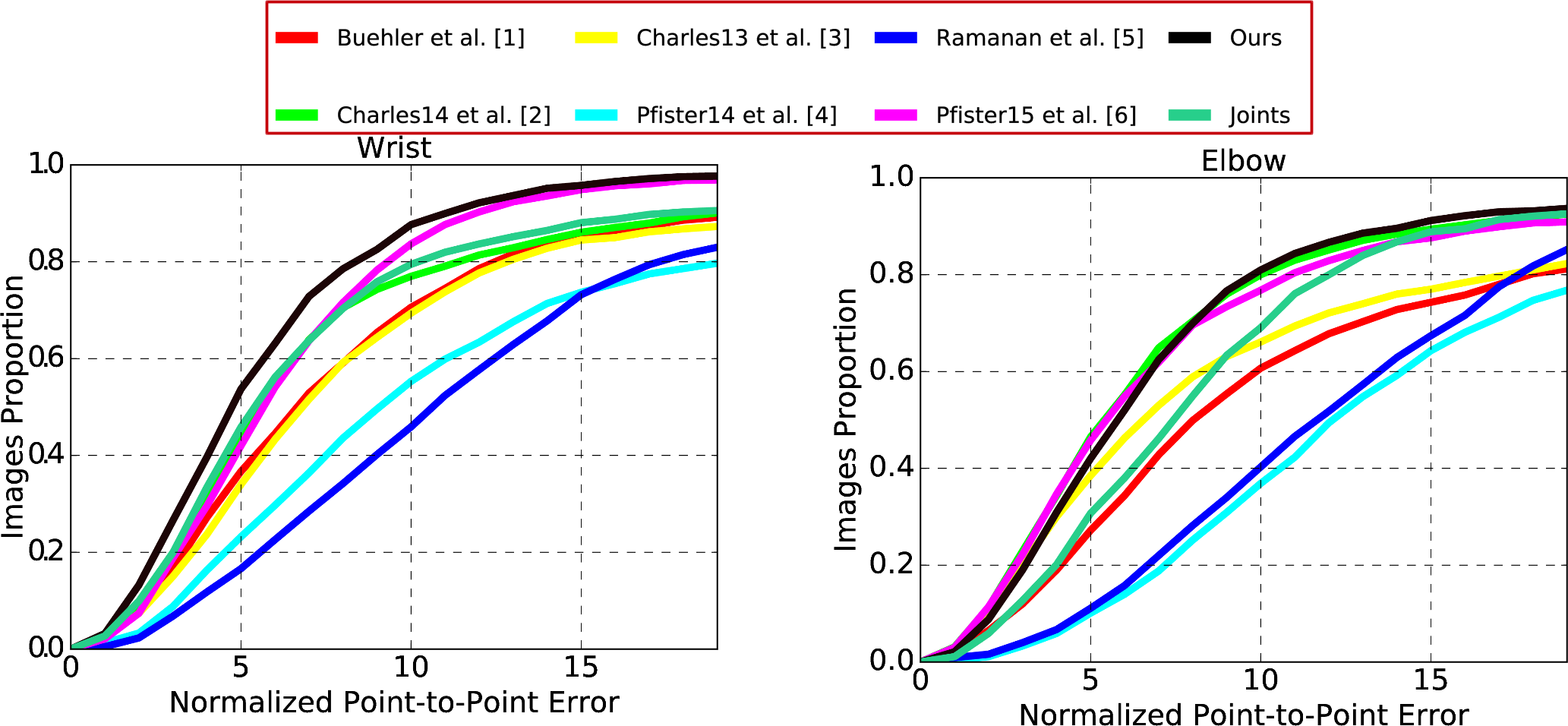
Figure 2: Cumulative error distributions over skeleton landmarks on BBC Pose database for the experiment.
Annotation Corrections
The experiment demonstrates that it is feasible to use the proposed arm model in order to correct the annotations provided by current datasets. As mentioned above there are inconsistencies in the annotations of MPII [7], Fashion Pose [8] and FLIC [9]. Due to the large variance in arm pose, it is difficult even for trained annotators to obtain consistent annotations between them.
By applying our outline patch-based AAM on the aforementioned databases, we managed to greatly correct the currently available annotations of the arm. Figure 3 shows indicative examples of the corrected landmarks. There is no doubt that points after correction demonstrate more consistency among images.

Figure 3: Demonstration of annotation correction using our method. Red dots refer to officially provided landmarks, and green dots are corrected position.
Contributions
- We propose one of the first, to the best of our knowledge, methodologies that constructs accurate SDMs from a set of training data with inconsistent annotations. We show that the proposed methodology tremendously reduces the manual workload thanks to the highly effective curve annotations.
- We illustrate the ability of the proposed method to generate consistent sparse landmark annotations for object classes which, by nature, make it impossible to be manually annotated in a consistent way.
- We show that it is more advantageous to model the human body parts (e.g. arms) with a set of sparse landmarks on their outline, rather than on their skeleton joints. This is because the outline landmarks, which can be acquired by our method in a straightforward way, exhibit better consistency compared to the inevitable inconsistency of the joint landmarks.
- We report state-of-the-art quantitative and qualitative results on human body parts localisation by employing a patch-based SDM trained on the outline landmarks that are sampled by the dense correspondences. Our proposed model outperforms all current state-of-the-art techniques that are trained on skeleton joints.
- We show that the employed patch-based SDM corrects the annotations that are currently provided for most major human body pose databases. (See Downloads secton for correction annotation)
For detailed information please refer to paper here.
References
[1] P. Buehler, M. Everingham, D. P. Huttenlocher, and A. Zisserman. Upper body detection and tracking in extended signing sequences. International journal of computer vision, 95(2):180–197, 2011.
[2] J. Charles, T. Pfister, D. Magee, D. Hogg, and A. Zisserman. Upper body pose estimation with temporal sequential forests. In Proceedings of the British Machine Vision Conference 2014, pages 1–12. BMVA Press, 2014.
[3] J. Charles, T. Pfister, D. Magee, D. Hogg, and A. Zisserman. Domain adaptation for upper body pose tracking in signed tv broadcasts. In Proceedings of the British machine vision conference, 2013.
[4] T. Pfister, K. Simonyan, J. Charles, and A. Zisserman. Deep convolutional neural networks for efficient pose estimation in gesture videos. In Computer Vision–ACCV 2014, pages 538–552. Springer, 2015.
[5] Y. Yang and D. Ramanan. Articulated human detection with flexible mixtures of parts. Pattern Analysis and Machine Intelligence, IEEE Transactions on, 35(12):2878–2890, 2013.
[6] T. Pfister, J. Charles, and A. Zisserman. Flowing convnets for human pose estimation in videos. In Proceedings of the IEEE International Conference on Computer Vision. 1913-1921, 2015.
[7] M. Andriluka, L. Pishchulin, P. Gehler, and B. Schiele. 2d human pose estimation: New benchmark and state of the art analysis. In IEEE Conference on Computer Vision and Pattern Recognition (CVPR), June 2014.
[8] M. Dantone, J. Gall, C. Leistner, and L. Van Gool. Human pose estimation using body parts dependent joint regressors. In Computer Vision and Pattern Recognition (CVPR), 2013 IEEE Conference on, pages 3041–3048. IEEE, 2013.
[9] B. Sapp and B. Taskar. Modec: Multimodal decomposable models for human pose estimation. In Computer Vision and Pattern Recognition (CVPR), 2013 IEEE Conference on, pages 3674–3681. IEEE, 2013.
[10] T. Pfister, J. Charles, and A. Zisserman. Flowing convnets for human pose estimation in videos. arXiv preprint arXiv:1506.02897, 2015.
[11] T.-Y. Lin, M. Maire, S. Belongie, J. Hays, P. Perona, D. Ramanan, P. Dollar, and C. L. Zitnick. Microsoft coco: Com- ´ mon objects in context. In Computer Vision–ECCV 2014, pages 740–755. Springer, 2014.
[12] L. Bourdev and J. Malik. Poselets: Body part detectors trained using 3d human pose annotations. In International Conference on Computer Vision, sep 2009.