Scope:
Most Facial Expression Recognition and Analysis systems proposed in the literature focus on the binary occurrence of expressions, often either basic emotions or FACS Action Units (AUs). In reality, expressions can vary greatly in intensity, and this intensity is often a strong cue for the interpretation of the meaning of expressions. In addition, despite efforts towards evaluations standards (e.g. FERA 2011), there still is a need for more standardised evaluation procedures. They therefore suffer from low comparability. This is in stark contrast with more established problems in human behaviour analysis from video such as face detection and face recognition. Yet at the same time, this is a rapidly growing field of research, due to the constantly increasing interest in applications for human behaviour analysis, and technologies for human-machine communication and multimedia retrieval.
In these respects, the FG 2015 Facial Expression Recognition and Analysis challenge (FERA2015) shall help raise the bar for expression recognition by challenging participants to estimate AU intensity, and it will continue to bridge the gap between excellent research on facial expression recognition and low comparability of results. We do this by means of three selected tasks: the detection of FACS Action Unit (AU) occurrence, the estimation of AU intensity for pre-segmented data (i.e. when AU occurrence is known), and fully automatic AU intensity estimation (i.e. for every frame when AU occurrence is not known).
The data used will be provided by the organisers, and is derived from two high-quality, non-posed databases: BP4D and SEMAINE. It consists of recordings of people displaying a range of expressions.
The corpus is provided as three strictly divided partitions: one training, one development, and one test partition. The test partition is constructed such that participating systems will be evaluated on both subject-dependent data and subject-independent data, as both situations occur frequently in real-life settings. The test partition will be held back by the organisers. Participants will send in their working programs and the organisers will run these on the test data. The training and development partitions will be available to the participants immediately. The reason for having a development partition is to allow participants to run a large number of studies on a commonly defined part of the fully labelled available data – it is perfectly fine to use the evaluation partition in training the final versions of a participants’ entry.
Please see the evaluation guidelines below to which all participants in the challenge should adhere. Baseline features will be released, as well as benchmark results of two basic approaches will be provided, which will act as a baseline. The first uses Local Gabor Binary Patterns from Three Orthogonal Planes features (LGBP-TOP), PCA and Support Vector Machines, and the second uses tracked fiducial facial points, PCA and Support Vector machines.
Three FACS AU based sub-challenges are addressed:
- Occurrence Sub-Challenge: Action Units have to be detected on frame basis.
- Pre-Segmented Intensity Sub-Challenge, the segments of AU occurrence can be assumed to be known, and the goal is to predict the intensity level for each frame when an AU occurs
- Fully Automatic Intensity Sub-Challenge, both the occurrence and intensity of AUs must be predicted for each frame of a video
In addition to participation to the challenge, we invite papers that address the benchmarking of facial expressions, open challenges in facial expression recognition in general, and FACS AU analysis in particular.
The organisers will write a paper outlining the challenge’s goals, guidelines, and baseline methods for comparison. This baseline paper, including the results of the baseline method on the test partitions, will be available from the challenge’s website from end October, 2014. To save space, participants are kindly requested to cite this paper instead of reproducing the results of that paper.
Both sub-challenges allow participants to extract their own features and apply their own classification algorithm on these. The labels of the test set will remain unknown throughout the competition, and participants will need to adhere to the specified training and parameter optimisation procedure. Participants will be allowed only three trials to upload their programs for evaluation on the test set. After each upload of results, the organisers will inform the participants by email about the performance attained by their system.
Organisers:
General Chairs:
Data Chairs:
- Jeff Girard, University of Pittsburgh
- Timur Almaev, University of Nottingham
- Bihan Jiang, Imperial College London
Programme committee:
Jeff Girard,
Pittsburgh University, USA
Hatice Gunez,
Queen Mary University London, UK
Qiang Ji,
Rensselaer Polytechnic Institute, USA
Brais Martinez,
University of Nottingham, UK
Louis-Philippe Morency,
Carnegie Mellon University, USA
Ognjen Rudovic,
Imperial College London, UK
Nicu Sebe,
University of Trento, IT
Yorgos Tzimiropoulos,
University of Nottingham, UK
Paper submission:
Please submit your paper through CMT: https://cmt.research.microsoft.com/FERA2015
Each participation will be accompanied by a paper presenting the results of a specific approach to facial expression analysis that will be subjected to a peer-review process. The organisers preserve the right to re-evaluate the findings, but will not participate themselves in the challenge. Participants are encouraged to compete in both sub-challenges. Please note that the first system submission must be done two weeks before the submission deadline to allow us to set up your code! Please read the challenge guidelines below carefully for more technical information about the challenge.
Papers should be 6 pages, and should adhere to the same formatting guidelines as the main FG2015 conference. The review process will be double blind. For important dates, please see below.
The results of the Challenge will be presented at the Facial Expression Recognition and Analysis Challenge 2015 Workshop to be held in conjunction with Automatic Face and Gesture Recognition 2015 in Ljubljana, Slovenia. Prizes will be awarded to the two sub-challenge winners.
If you are interested and planning to participate in the FERA2015 Challenge, or if you want to be kept informed about the Challenge, please send the organisers an e-mail to indicate your interest and visit the homepage:
http://sspnet.eu/FERA2015
Thank you and best wishes,
Michel Valstar, Jeff Cohn, Lijun Yin, Gary McKeown, Marc Méhu, and Maja Pantic
Call for Participation:
The second Facial Expression Recognition and Analysis challenge FERA 2015 , held in conjunction with FG 2015 is calling for contributions in the form of papers and competition in the challenge. The challenge has two components: detection of the presence of a set of FACS Action Units (facial muscle actions), and estimation of FACS Action Unit intensity. Participants are invited to participate in one or more of the sub-challenges.
For more information about the challenge, see http://sspnet.eu/fera2015/ . To register for the challenge data please create an account for both the FERA 2015 dataset and the SEMAINE database.
Submission deadlines can be found below.
In addition to challenge contributions the FERA 2015 workshop calls for papers that do not compete in the challenge but that address related topics, e.g.:
* AU activation detection
* AU intensity estimation
* Temporal dynamics of AUs
* Benchmarking of facial expressions
* Novel applications using automatic Action Unit analysis
* Publicly available AU databases
Regarding the review process, papers competing in the challenge have lower novelty requirements than would be expected from a normal FG workshop. Besides correctness and readability, both performance on the challenge and novelty will be taken into account in the peer review process. Papers not competing in the challenge will be evaluated as usual.
Challenge Guidelines:
Many details about the data, performance measures, and baseline features and prediction results are included in the baseline paper, which is now available for download. Note that the paper is work in progress. While it may not be complete, we aim to keep it factually correct at all times.
Download the data
Create an account to download the training and development partitions from the FERA 2015 data website.
You will have to sign two EULAs: one for the BP4D data, and one for the SEMAINE database. You should first create a SEMAINE account to sign that EUlA, before creating the FERA 2015 account and signing the BP4D EULA. Send the latter to the organisers by email. Please also register your team at this point.
Details of the datasets
BP4D labels
For the BP4D data there are two types of FACS annotation files: occurrence and intensity files.
Each video file has a single occurrence annotation file which contains the annotations for all action units. The occurrence files are in the CSV format and are essentially numerical matrices in which each column corresponds to a single action unit and each row corresponds to a single video frame. The files also contain a header row with action unit labels and a header column with frame numbers. The proper way to parse these files is to drop the headers and then index for the video frame(s) and action unit(s) of interest. The following examples in MATLAB code may be helpful:
OCC = csvread(’F001_T1.csv’); %import annotations for one video file
FRNO = OCC(2:end,1); %get all frame numbers
CODES = OCC(2:end,2:end); %get codes for all action units
AU12 = CODES(:,12); %index action unit 12 codes for all video frames
FR10 = CODES(FRNO==10,:); %index all action unit codes for video frame 10
AU12_FR10 = CODES(FRNO==10,12); %index code for action unit 12 for video frame 10
The occurrence codes themselves are either 0 for absent, 1 for present, or 9 for missing data (unknown). Codes will be missing when the video frame was not coded by the manual annotator (not all frames and AUs were).
Each video file has multiple intensity annotation files: one per action unit. The action unit annotated in each file is indicated in its file name. The intensity files are also in the CSV format and are essentially numerical vectors in which each row corresponds to a single video frame. These files have no header rows or columns. The row number corresponds to the actual video frame number. The following examples in MATLAB code may be helpful:
INT = csvread(’2F02_01_AU12_DR.csv’); %import annotations for one video file
AU12_FR10 = INT(10); %index code for action unit 12 for video frame 10
The intensity codes themselves are either 0 for absent, 1 for present at the A level, 2 for present at the B level, 3 for present at the C level, 4 for present at the D level, 5 for present at the E level, or 9 for missing data (unknown). Codes will be missing when the video frame was not coded by the manual annotator (not all frames were) and when the face was occluded during the video frame.
SEMAINE labels
We have now prepared Matlab code for reading SEMAINE AU annotations, please find it attached below.
As you already know in this year challenge half of the data comes from the SEMAINE database. These data have been annotated using the ELAN annotation toolbox (https://tla.mpi.nl/tools/tla-tools/elan/), which stores annotations in XML structures saved in files with “.eaf” extension. Despite the extension, ELAN annotation files could be opened with any text editor and parsed with almost any XML parser available today. There are also files with “.pfsx” extension accompanying annotations, which are safe to ignore.
Inside the XML structure ELAN stores annotations in so-called tiers. There is a tier for speech and two tiers for every AU, one is for activations and another one is for intensity levels. Given that SEMAINE has been annotated for the total of 32 AUs, this gives 65 tiers. Since SEMAINE data is not going to be used in the intensity sub-challenge, we are going to ignore all intensity tiers as well as speech tier. We are also going to ignore most of the activation tiers as only the subset of 6 AUs (2, 12, 17, 25, 28, 45) has been chosen for this challenge from this database.
Regarding annotation rules during speech: when there’s speech we do not code the lower face AUs. This is the same procedure as we used for FERA 2011. The annotation files provide annotation for the occurrence of speech. For the purpose of score calculation, lower face AU scoring will be ignored during periods of speech.
Each tier is a combination of activation periods represented with two time stamps – when it starts and when it stops. Each time stamp refers to a particular time slot, table of which is defined in the beginning of the annotation file. A time slot has a numerical value in milliseconds which could be converted to frames by dividing time in ms by 1000 and multiplying the resulting value by the framerate. All SEMAINE videos have a constant framerate of 50 FPS.
The sample code written in Matlab takes a complete path to an ELAN annotation file, loads the XML structure, reads all time slots and converts time in ms into frames. It then goes through the above subset of 6 AUs and returns a numerical matrix of size NUMBER OF FRAMES by NUMBER OF ACTION UNITS, where each row represents a frame and each column is an AU. The matrix holds binary activation status for each frame / AU combination. The matrix also has a column header showing which AU corresponds to which column as well as a row header displaying original frame indexes.
The code requires an open source 3rdparty XML parser to work properly, which is included with the package.
Participant Registration
Please register your team with the organisers, by emailing Timur Almaev. When submitting your EULA for the data, please also provide a team name, the team leader, and for every person on the team a name and affiliation.
Participant System Submission
In FERA 2015, all participants must send in their fully working program. The program must be able to process data of the same format as the training and development partitions. We will later provide a function call signature that must be included in your program. We aim to support systems developed for Mac, Windows, and Linux.
Because of this flexibility, we ask you to work with us to get your programs working on our systems. We accept both compiled and source code entries. Please submit your first version two weeks before the paper submission deadline, to allow us time to set up your code. After your first submission, your scores will be sent to you within 48 hours of submission of a new system.
Participants can submit up to five systems. This is regardless of whether they are small tweaks of the same approach, or wildly different approaches. Any low-level comparisons and parameter optimisations should be done using the training and development partitions.
Important Dates:
|
|
1 October, 2014 |
- Release of training/development data:
|
22 October, 2014 |
- Releases of first preliminary baseline paper:
|
30 October, 2014 |
- Paper submission deadline:
|
12 January 26 January, 2015, 23:59 PST |
- Notification of acceptance:
|
11 February 25 February, 2015 |
|
|
18 February 4 March, 2015 |
|
|
Monday 4 May, room E2 |
Programme:
The FERA 2015 workshop will be a full-day event held on Monday 4 May 2015 in room E3, same venue as the main FG 2015 conference. The day will start with a keynote speech, followed by an introduction to the challenge, a series of paper presentations and an overview of the challenge results and an announcement of the winners of the two sub-challenges. The day will be closed by a panel session to discuss the future of AU analysis and facial expression recognition challenges in particular.
———————————————–
9:30-10:30: Keynote (Prof Qiang Ji, Rensselaer Polytechnic Institute, USA)
———————————————–
10:30 – 11:00 am: Coffee Break
———————————————–
Session 1 – Action Unit Occurrence Detection:
11:00 – 11:20: FERA 2015 challenge introduction
11:20 – 11:40: Deep Learning based FACS Action Unit Occurrence and Intensity Estimation – Amogh Gudi, Tasli Emrah, Tim Den Uyl, Andreas Maroulis
11:40 – 12:00: Learning to combine local models for Facial Action Unit detection – Shashank Jaiswal, Brais Martinez, Michel Valstar
12:00 – 12:20: Discriminant Multi-Label Manifold Embedding for Facial Action Unit Detection – Anil Yuce, Hua Gao, Jean-Philippe Thiran
———————————————–
12:20 – 13:30 am: Lunch Break
———————————————–
Session 2 – Action Unit Intensity Estimation:
13:30 – 13:50: Facial Action Units Intensity Estimation by the Fusion of Features with Multi-kernel Support Vector Machine – Zuheng Ming, Aurélie Bugeau, Jean-Luc Rouas, Takaaki Shochi
13:50 – 14:10: Cross-dataset learning and person-specific normalisation for automatic Action Unit detection – Tadas Baltrusaitis, Marwa Mahmoud, Peter Robinson
14:10 – 14:30: Facial Action Unit Intensity Prediction via Hard Multi-Task Metric Learning for Kernel Regression – Jeremie Nicolle, Kevin Bailly, Mohamed Chetouani
14:30 – 14:45: Challenge results
———————————————–
14:45 – 15:30 Panel Session
———————————————–
- Fernando de la Torre
- Qiang Ji
- Matthew Turk
Keynote: Exploiting Facial Muscular Movement Dependencies for Robust Facial Action Recognition, Prof Qiang Ji
Abstract:
Facial action (AU) unit recognition is concerned with recognizing the local facial motions from image or video. Facial action recognition is challenging, in particular for recognizing spontaneous facial actions due to subtle facial motions, frequent head movements, and ambiguous and uncertain facial motion measurements. Because of the underlying anatomic facial structure as well as the need to produce a meaningful and natural facial expression, facial muscles often move in a synchronized and coordinated manner. Recognizing this fact, we propose to develop probabilistic AU models to systematically capture the spatiotemporal dependences among the facial muscles and leverage the captured facial action relations for robust and accurate facial action recognition. In this talk, I will discuss our recent work in this area. Our research in this area can be divided into data-based AU models and knowledge-based AU models. For data-based AU models, I will first discuss our earlier work that involves using Dynamic Bayesian Network to capture the local spatial temporal relationships among AUs. I will then discuss our recent work that uses Restricted Boltzmann Machine (RBM) to capture the high order and global relationships among AUs.
The data-based AU models depend on the training data. Their performance suffers if the training data is lacking in either quality or quantity. More importantly, the data-based AU models cannot generalize well beyond the data that are used to train them. To overcome this limitation, we introduce the knowledge-based AU model, where we propose to learn the AU relationships exclusively from generic facial anatomic knowledge that governs AU behaviors, without any training data. For knowledge-based AU models, I will discuss the related anatomic knowledge as well as our methods to capture such knowledge and to encode it into the AU models. Finally, I will discuss the experimental evaluations of our AU models on benchmark datasets and their performance against state of the art methods.
Biography:
Qiang Ji received his Ph.D degree in Electrical Engineering from the University of Washington. He is currently a Professor with the Department of Electrical, Computer, and Systems Engineering at Rensselaer Polytechnic Institute (RPI). From 2009 to 2010, he served as a program director at the National Science Foundation (NSF), where he managed NSF’s computer vision and machine learning programs. He also held teaching and research positions with the Beckman Institute at University of Illinois at Urbana-Champaign, the Robotics Institute at Carnegie Mellon University, the Dept. of Computer Science at University of Nevada at Reno, and the US Air Force Research Laboratory. Prof. Ji currently serves as the director of the Intelligent Systems Laboratory (ISL) at RPI.
Prof. Ji’s research interests are in computer vision, probabilistic graphical models, pattern recognition, and their applications in various fields. He has published over 200 papers in peer-reviewed journals and conferences, and he has received multiple awards for his work. His research has been supported by major governmental agencies including NSF, NIH, DARPA, ONR, ARO, and AFOSR as well as by major companies. Prof. Ji is an editor on several related IEEE and international journals and he has served as a general chair, program chair, technical area chair, and program committee member in numerous international conferences/workshops. Prof. Ji is a fellow of the IEEE and the IAPR.
Results:
The FERA2015 occurrence sub-challenge results in terms of F1 score are shown in the graph below.
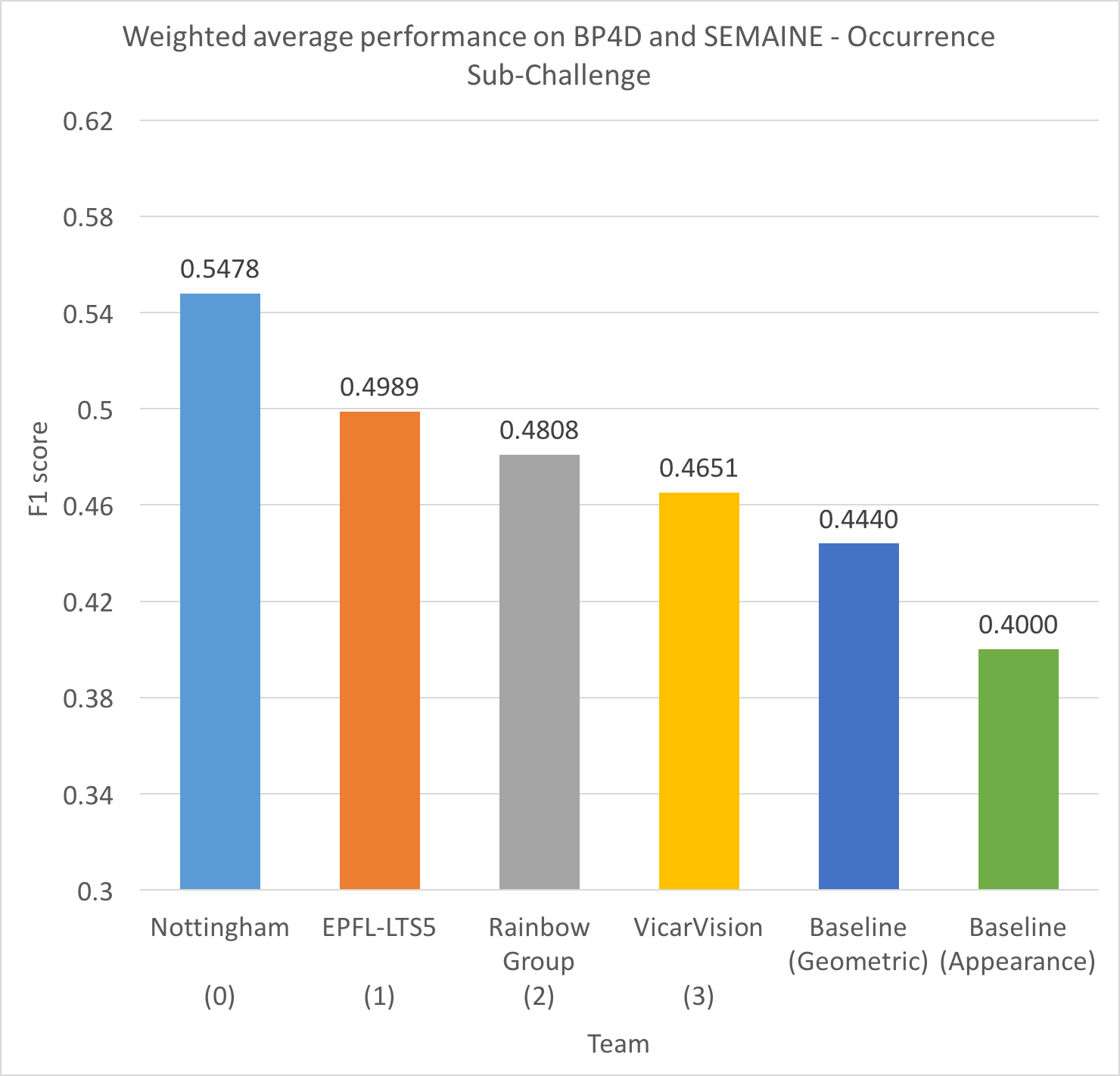
For the new best-performing paper, please refer to:
Shashank Jaiswal and Michel Valstar, 'Deep Learning the Dynamic Appearance and Shape of Facial Action Units', Winter Conference on Applications of Computer Vision (WACV), 2016
The FERA2015 intensity sub-challenge results in terms of ICC score are shown in the graph below.
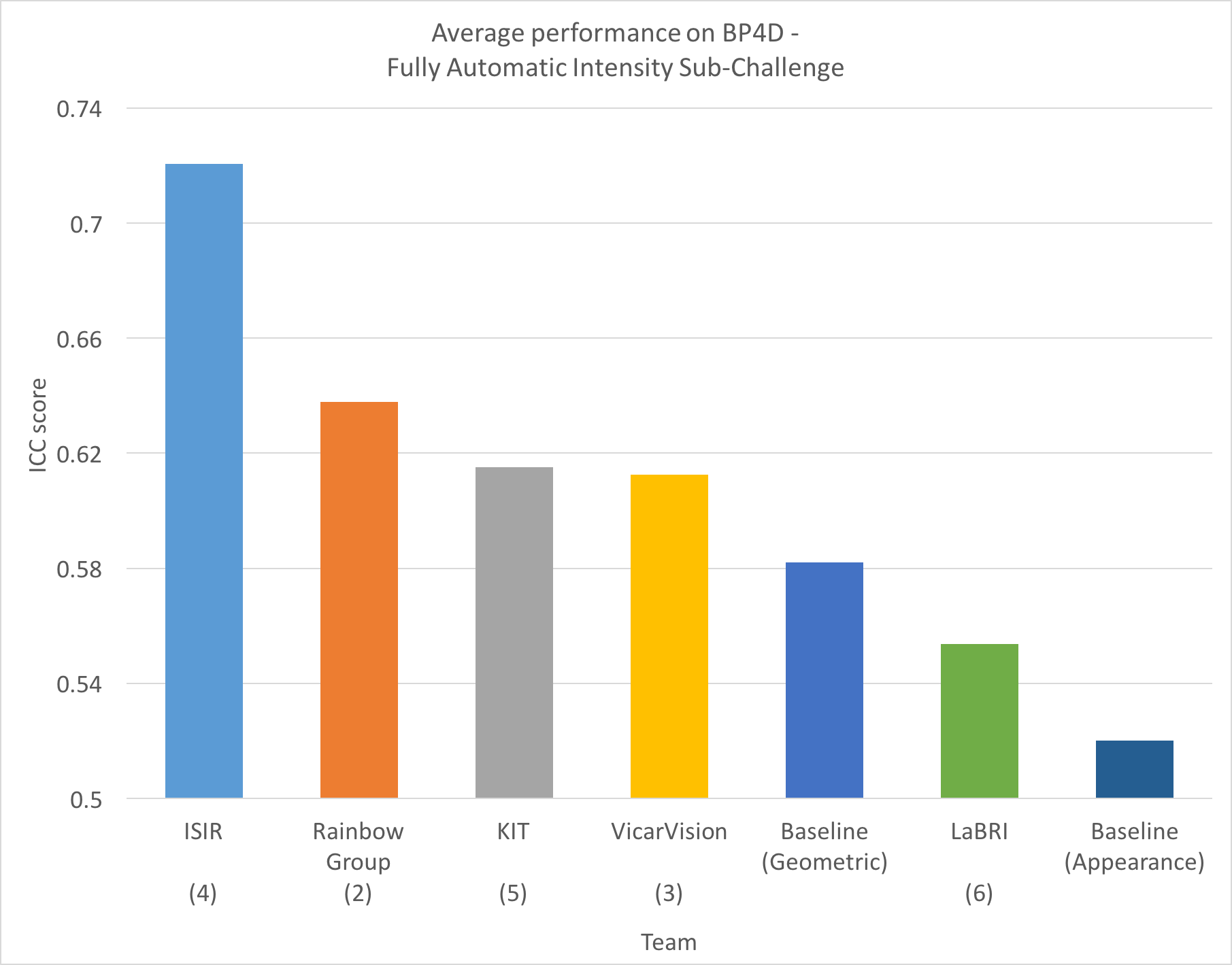
Sponsors:
The FERA 2015 workshop and challenge has been generously supported by Horizon 2020 SEWA project.

