Datasets
- CVPR 2023: 5th Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW)
- ECCV 2022: 4th Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW)
- CVPR 2022: 3rd Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW)
- ICCV 2021: 2nd Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW)
- Synthesizing Coupled 3D Face Modalities by TBGAN
- Face Bio-metrics under COVID (Masked Face Recognition Challenge & Workshop ICCV 2021)
- First Affect-in-the-Wild Challenge
- Aff-Wild2 database
- FG-2020 Competition: Affective Behavior Analysis in-the-wild (ABAW)
- First Faces in-the-wild Workshop-Challenge
- In-The-Wild 3D Morphable Models: Code and Data
- Sound of Pixels
- Lightweight Face Recognition Challenge & Workshop (ICCV 2019)
- Audiovisual Database of Normal-Whispered-Silent Speech
- Deformable Models of Ears in-the-wild for Alignment and Recognition
- 300 Videos in the Wild (300-VW) Challenge & Workshop (ICCV 2015)
- 1st 3D Face Tracking in-the-wild Competition
- The Fabrics Dataset
- The Mobiface Dataset
- Large Scale Facial Model (LSFM)
- AgeDB
- AFEW-VA Database for Valence and Arousal Estimation In-The-Wild
- The CONFER Database
- Special Issue on Behavior Analysis "in-the-wild"
- Body Pose Annotations Correction (CVPR 2016)
- KANFace
- MeDigital
- FG-2020 Workshop "Affect Recognition in-the-wild: Uni/Multi-Modal Analysis & VA-AU-Expression Challenges"
- 4DFAB: A Large Scale 4D Face Database for Expression Analysis and Biometric Applications
- Affect "in-the-wild" Workshop
- 2nd Facial Landmark Localisation Competition - The Menpo BenchMark
- Facial Expression Recognition and Analysis Challenge 2015
- The SEWA Database
- Mimic Me
- 300 Faces In-The-Wild Challenge (300-W), IMAVIS 2014
- MAHNOB-HCI-Tagging database
- 300 Faces In-the-Wild Challenge (300-W), ICCV 2013
- MAHNOB Laughter database
- MAHNOB MHI-Mimicry database
- Facial point annotations
- MMI Facial expression database
- SEMAINE database
- iBugMask: Face Parsing in the Wild (ImaVis 2021)
- iBUG Eye Segmentation Dataset
Code
- Valence/Arousal Online Annotation Tool
- The Menpo Project
- The Dynamic Ordinal Classification (DOC) Toolbox
- Gauss-Newton Deformable Part Models for Face Alignment in-the-Wild (CVPR 2014)
- Robust and Efficient Parametric Face/Object Alignment (2011)
- Discriminative Response Map Fitting (DRMF 2013)
- End-to-End Lipreading
- DS-GPLVM (TIP 2015)
- Subspace Learning from Image Gradient Orientations (2011)
- Discriminant Incoherent Component Analysis (IEEE-TIP 2016)
- AOMs Generic Face Alignment (2012)
- Fitting AAMs in-the-Wild (ICCV 2013)
- Salient Point Detector (2006/2008)
- Facial point detector (2010/2013)
- Chehra Face Tracker (CVPR 2014)
- Empirical Analysis Of Cascade Deformable Models For Multi-View Face Detection (IMAVIS 2015)
- Continuous-time Prediction of Dimensional Behavior/Affect
- Real-time Face tracking with CUDA (MMSys 2014)
- Facial Point detector (2005/2007)
- Facial tracker (2011)
- Salient Point Detector (2010)
- AU detector (TAUD 2011)
- Action Unit Detector (2016)
- AU detector (LAUD 2010)
- Smile Detectors
- Head Nod Shake Detector (2010/2011)
- Gesture Detector (2011)
- Head Nod Shake Detector and 5 Dimensional Emotion Predictor (2010/2011)
- Gesture Detector (2010)
- HCI^2 Framework
- FROG Facial Tracking Component
- SEMAINE Visual Components (2008/2009)
- SEMAINE Visual Components (2009/2010)
AFEW-VA Database for Valence and Arousal Estimation In-The-Wild

Fig 1: Representative sample images from the AFEW-VA Dataset.
This page contains the data accompanying the paper titled 'AFEW-VA database for valence and arousal estimation In-The-Wild'.
The AFEW-VA databaset is a collection of highly accurate per-frame annotations levels of valence and arousal, along with per-frame annotations of 68 facial landmarks for 600 challenging video clips. These clips are extracted from feature films and were also annotated in terms of discrete emotion categories in the form of the AFEW database (that can be obtained there).
The accurate annotations of valance, arousal and facial landmarks together with the frames of the clips to which these annotations belong can be obtained from the files listed below.
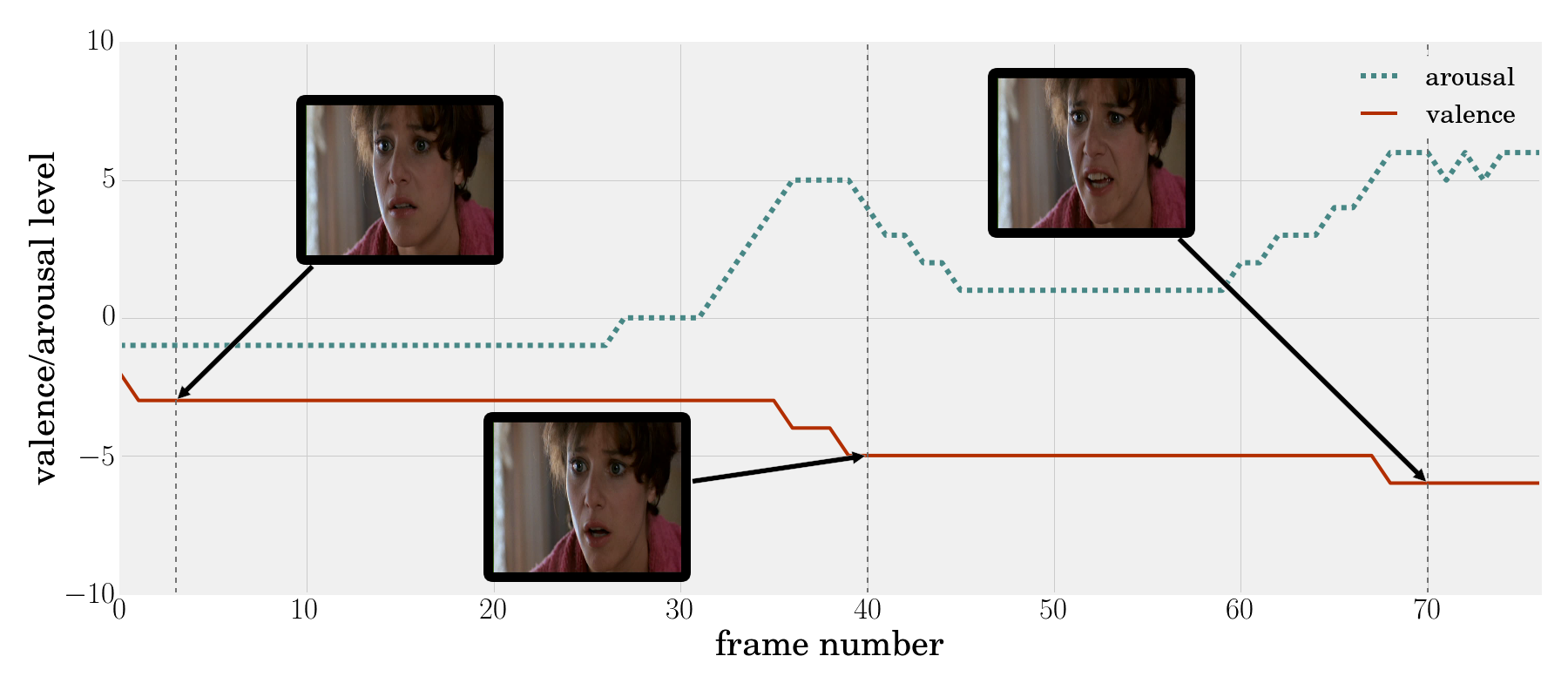
Fig 2: Sample video from the AFEW-VA Dataset.
Each of the zip files contains 50 annotated videos:
- AFEW-VA/01.zip (Clips 1-50)
- AFEW-VA/02.zip (Clips 51-100)
- AFEW-VA/03.zip (Clips 101-150)
- AFEW-VA/04.zip (Clips 151-200)
- AFEW-VA/05.zip (Clips 201-250)
- AFEW-VA/06.zip (Clips 251-300)
- AFEW-VA/07.zip (Clips 301-350)
- AFEW-VA/08.zip (Clips 351-400)
- AFEW-VA/09.zip (Clips 401-450)
- AFEW-VA/10.zip (Clips 451-500)
- AFEW-VA/11.zip (Clips 501-550)
- AFEW-VA/12.zip (Clips 551-600)
The AFEW-VA database is provided for research purposes only.
If you use this data, please cite:
[1] J. Kossaifi, G. Tzimiropoulos, S. Todorovic and M. Pantic, "AFEW-VA database for valence and arousal estimation in-the-wild", in Image and Vision Computing, 2017.
[2] A. Dhall, R. Goecke, S. Lucey and T. Gedeon, "Collecting Large, Richly Annotated Facial-Expression Databases from Movies," in IEEE MultiMedia, vol. 19, no. 3, pp. 34-41, July-Sept. 2012.