Human activity detection and its application to social signals detection
In this part of our research we propose a voting scheme in the space-time domain that allows both the temporal and spatial localization of activities. Our method uses an implicit representation of the spatiotemporal shape of an activity that relies on the spatiotemporal localization of ensembles of spatiotemporal features. The latter are localized around spatiotemporal salient points. We compare feature ensembles using a star graph model that compensates for scale changes using the scales of the features within each ensemble. We use boosting in order to create codebooks of characteristic ensembles for each class. Subsequently, we match the selected codewords with the training sequences of the respective class, and store the spatiotemporal positions at which each codeword is activated. This is performed with respect to a set of reference points, (e.g. the center of the torso and the lower bound of the subject) and with respect to the start/end of the action instance.

Voting example. (a) During training, the position θd and average spatiotemporal scale Sd of the activated ensemble is stored with respect to one or more reference points (e.g., the center of the subject, marked with the blue cross). (b) During testing, votes are cast using the stored θd values, normalized by SqSd−1 in order to account for scale changes.
In this way, we create class-specific spatiotemporal models that encode the spatiotemporal positions at which each codeword is activated in the training set. During testing, each activated codeword casts probabilistic votes to the location in time where the activity starts and ends, as well as towards the location of the utilized reference points in space. In this way a set of class-specific voting spaces is created. We use Mean Shift at each voting space in order to extract the most probable hypotheses concerning the spatiotemporal extend of the activities.
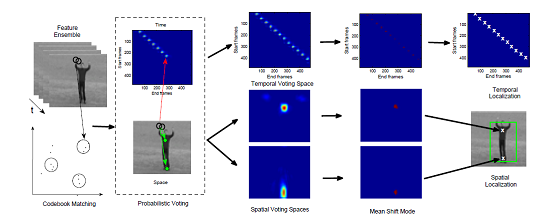
Overview of the spatiotemporal voting process
Each hypothesis is subsequently verified by performing action category classification with a Relevance Vector Machine (RVM).
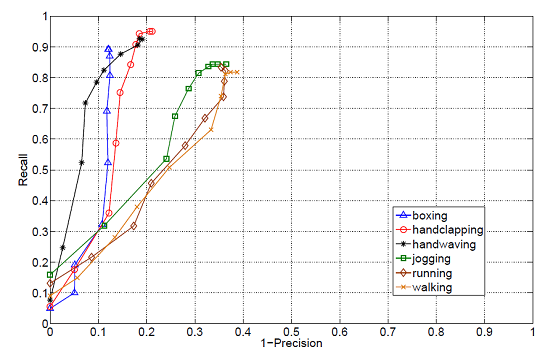
Joint Localization and recognition: ROC curves corresponding to each class of the KTH dataset.
The proposed method was also used for the detection of social signals in image sequences depicting political debates. More specifically we performed experiments on hand-raising detection. Hand raising activities in political debates could potentially be an important cue for agreement/disagreement detection. Here, we consider a single raising and lowering of the speaker’s hand as a single hand-raising activity instance. We used 10 hand raising instances in order to train the corresponding model, and tested the proposed algorithm on 20 test sequences of political debates. The latter include view-point and scene changes, camera zoom and videos where the onset and offset of the action were out of the camera’s view. The localization results that we achieved, and a still frame of a hand raising instance is shown in the following figure:

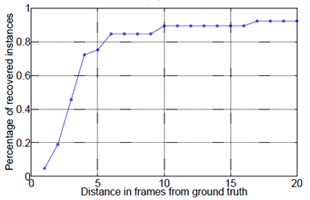
As can be seen, the proposed algorithm was able to localize 90% of the extracted hypotheses within 10 frames from the ground truth annotation.
Involved group members
Maja Pantic, Konstantinos Bousmalis, Aaron C. Elkins, Antonis Oikonomopoulos
Related Publications
-
Spatiotemporal Localization and Categorization of Human Actions in Unsegmented Image Sequences
A. Oikonomopoulos, I. Patras, M. Pantic. IEEE Transactions on Image Processing. 20(4): pp. 1126 - 1140, April 2011.
Bibtex reference [hide]@article{Oikonomopoulos10,
author = {A. Oikonomopoulos and I. Patras and M. Pantic},
pages = {1126--1140},
journal = {IEEE Transactions on Image Processing},
month = {April},
number = {4},
title = {Spatiotemporal Localization and Categorization of Human Actions in Unsegmented Image Sequences},
volume = {20},
year = {2011},
}Endnote reference [hide]%0 Journal Article
%T Spatiotemporal Localization and Categorization of Human Actions in Unsegmented Image Sequences
%A Oikonomopoulos, A.
%A Patras, I.
%A Pantic, M.
%J IEEE Transactions on Image Processing
%D 2011
%8 April
%V 20
%N 4
%F Oikonomopoulos10
%P 1126-1140 -
Discriminative Space-time Voting for Joint Recognition and Localization of Actions
A. Oikonomopoulos, I. Patras, M. Pantic. Proceedings ACM Int'l Workshop on Social Signal Processing (SSPW'10), Firenze, Italy. October 2010.
Bibtex reference [hide]@inproceedings{Oikonomopoulos2010dsvfj,
author = {A. Oikonomopoulos and I. Patras and M. Pantic},
booktitle = {Proceedings ACM Int'l Workshop on Social Signal Processing (SSPW'10), Firenze, Italy},
month = {October},
title = {Discriminative Space-time Voting for Joint Recognition and Localization of Actions},
year = {2010},
}Endnote reference [hide]%0 Conference Proceedings
%T Discriminative Space-time Voting for Joint Recognition and Localization of Actions
%A Oikonomopoulos, A.
%A Patras, I.
%A Pantic, M.
%B Proceedings ACM Int?l Workshop on Social Signal Processing (SSPW?10), Firenze, Italy
%D 2010
%8 October
%F Oikonomopoulos2010dsvfj -
Sparse B-spline polynomial descriptors for human activity recognition
A. Oikonomopoulos, M. Pantic, I. Patras. Image and Vision Computing Journal. 27(12): pp. 1814 - 1825, 2009.
Bibtex reference [hide]@article{Oikonomopoulos2009sbpdf,
author = {A. Oikonomopoulos and M. Pantic and I. Patras},
pages = {1814--1825},
journal = {Image and Vision Computing Journal},
number = {12},
title = {Sparse B-spline polynomial descriptors for human activity recognition},
volume = {27},
year = {2009},
}Endnote reference [hide]%0 Journal Article
%T Sparse B-spline polynomial descriptors for human activity recognition
%A Oikonomopoulos, A.
%A Pantic, M.
%A Patras, I.
%J Image and Vision Computing Journal
%D 2009
%V 27
%N 12
%F Oikonomopoulos2009sbpdf
%P 1814-1825 -
An implicit spatiotemporal shape model for human activity localisation and recognition
A. Oikonomopoulos, I. Patras, M. Pantic. Proceedings of IEEE Int'l Conf. Computer Vision and Pattern Recognition (CVPR-W'09). Miami, Florida, USA, 3: pp. 27 - 33, June 2009.
Bibtex reference [hide]@inproceedings{Oikonomopoulos2009aissm,
author = {A. Oikonomopoulos and I. Patras and M. Pantic},
pages = {27--33},
address = {Miami, Florida, USA},
booktitle = {Proceedings of IEEE Int'l Conf. Computer Vision and Pattern Recognition (CVPR-W'09)},
month = {June},
title = {An implicit spatiotemporal shape model for human activity localisation and recognition},
volume = {3},
year = {2009},
}Endnote reference [hide]%0 Conference Proceedings
%T An implicit spatiotemporal shape model for human activity localisation and recognition
%A Oikonomopoulos, A.
%A Patras, I.
%A Pantic, M.
%B Proceedings of IEEE Int?l Conf. Computer Vision and Pattern Recognition (CVPR-W?09)
%D 2009
%8 June
%V 3
%C Miami, Florida, USA
%F Oikonomopoulos2009aissm
%P 27-33 -
Trajectory-based Representation of Human Actions
A. Oikonomopoulos, I. Patras, M. Pantic, N. Paragios. editors: T. Huang, A. Nijholt, M. Pantic, A. Pentland. Lecture Notes in Artificial Intelligence, Special Volume on Artificial Intelligence for Human Computing. vol. 4451, pp. 133 - 154, 2007.
Bibtex reference [hide]@inbook{Oikonomopoulos2007troha,
author = {A. Oikonomopoulos and I. Patras and M. Pantic and N. Paragios},
pages = {133--154},
booktitle = {Lecture Notes in Artificial Intelligence, Special Volume on Artificial Intelligence for Human Computing},
editor = {T. Huang and A. Nijholt and A. Pentland and M. Pantic},
title = {Trajectory-based Representation of Human Actions},
volume = {4451},
year = {2007},
}Endnote reference [hide]%0 Book Section
%A Oikonomopoulos, A.
%A Patras, I.
%A Pantic, M.
%A Paragios, N.
%E Huang, T.
%E Nijholt, A.
%E Pentland, A.
%E Pantic, M.
%B Lecture Notes in Artificial Intelligence, Special Volume on Artificial Intelligence for Human Computing
%D 2007
%V 4451
%F Oikonomopoulos2007troha
%P 133-154 -
Human Body Gesture Recognition using Adapted Auxiliary Particle Filtering
A. Oikonomopoulos, M. Pantic. Proceedings of IEEE Int'l Conf. Advanced Video and Signal based Surveillance (AVSS'07). London, UK, pp. 441 - 446, September 2007.
Bibtex reference [hide]@inproceedings{Oikonomopoulos2007hbgru,
author = {A. Oikonomopoulos and M. Pantic},
pages = {441--446},
address = {London, UK},
booktitle = {Proceedings of IEEE Int'l Conf. Advanced Video and Signal based Surveillance (AVSS'07)},
month = {September},
title = {Human Body Gesture Recognition using Adapted Auxiliary Particle Filtering},
year = {2007},
}Endnote reference [hide]%0 Conference Proceedings
%T Human Body Gesture Recognition using Adapted Auxiliary Particle Filtering
%A Oikonomopoulos, A.
%A Pantic, M.
%B Proceedings of IEEE Int?l Conf. Advanced Video and Signal based Surveillance (AVSS?07)
%D 2007
%8 September
%C London, UK
%F Oikonomopoulos2007hbgru
%P 441-446