Spatio-temporal action recognition using B-Splines
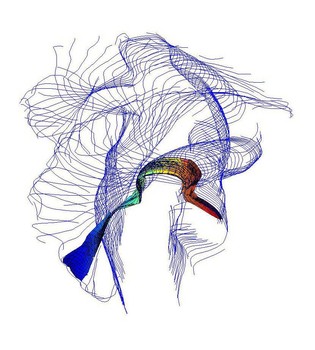
In this part of our research, we propose a set of novel visual descriptors that are derived from a set of detected spatiotemporal salient points. The salient points that we extract, correspond to areas where independent motion occurs, like ongoing activities in the scene. Centered at each salient point, we define a spatiotemporal neighborhood whose dimensions are proportional to the detected space-time scale of the point. Then, a three-dimensional piecewise polynomial, namely a B-spline, is fitted at the locations of the salient points that fall within this neighborhood. Our descriptors are subsequently derived as the partial derivatives of the resulting polynomial.
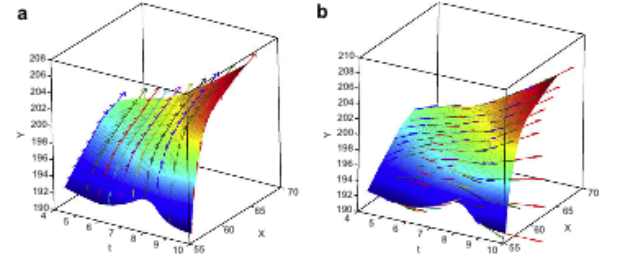
First derivatives along two directions of a B-spline polynomial, plotted as 3-dimensional vectors.
At the next step, the set of descriptors extracted from each spline is accumulated into a number of histograms. This number depends on the maximum degree of the partial derivatives. Since our descriptors correspond to geometric properties of the spline, they are translation invariant. Furthermore, the use of the automatically detected space-time scales of the salient points for the definition of the neighborhood ensures invariance to space and time scaling. Subsequently, we create we create a codebook of visual verbs by clustering our motion descriptors across the whole dataset, where a visual verb corresponds to a combined shape and motion descriptor. Each video in our dataset is then represented as a histogram of visual verbs. We use a kernel based classifier, namely the Relevance Vector Machine (RVM) , in order to classify test examples into one of the classes present in the training dataset. We evaluate the proposed method on publicly available human action datasets, like the Weizmann and KTH datasets.
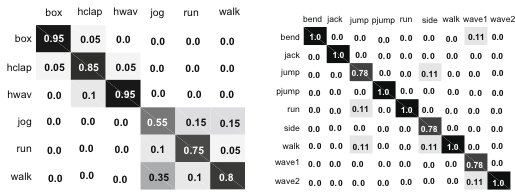
Confusion matrices for the KTH and Weizmann datasets.
Involved group members
Related Publications
-
Sparse B-spline polynomial descriptors for human activity recognition
A. Oikonomopoulos, M. Pantic, I. Patras. Image and Vision Computing Journal. 27(12): pp. 1814 - 1825, 2009.
Bibtex reference [hide]@article{Oikonomopoulos2009sbpdf,
author = {A. Oikonomopoulos and M. Pantic and I. Patras},
pages = {1814--1825},
journal = {Image and Vision Computing Journal},
number = {12},
title = {Sparse B-spline polynomial descriptors for human activity recognition},
volume = {27},
year = {2009},
}Endnote reference [hide]%0 Journal Article
%T Sparse B-spline polynomial descriptors for human activity recognition
%A Oikonomopoulos, A.
%A Pantic, M.
%A Patras, I.
%J Image and Vision Computing Journal
%D 2009
%V 27
%N 12
%F Oikonomopoulos2009sbpdf
%P 1814-1825 -
Human Gesture Recognition using Sparse B-spline Polynomial Representations
A. Oikonomopoulos, M. Pantic, I. Patras. Proceedings of Belgium-Netherlands Conf. Artificial Intelligence (BNAIC'08). Boekelo, the Netherlands, pp. 193 - 200, October 2008.
Bibtex reference [hide]@inproceedings{Oikonomopoulos2008hgrus,
author = {A. Oikonomopoulos and M. Pantic and I. Patras},
pages = {193--200},
address = {Boekelo, the Netherlands},
booktitle = {Proceedings of Belgium-Netherlands Conf. Artificial Intelligence (BNAIC'08)},
month = {October},
title = {Human Gesture Recognition using Sparse B-spline Polynomial Representations},
year = {2008},
}Endnote reference [hide]%0 Conference Proceedings
%T Human Gesture Recognition using Sparse B-spline Polynomial Representations
%A Oikonomopoulos, A.
%A Pantic, M.
%A Patras, I.
%B Proceedings of Belgium-Netherlands Conf. Artificial Intelligence (BNAIC?08)
%D 2008
%8 October
%C Boekelo, the Netherlands
%F Oikonomopoulos2008hgrus
%P 193-200 -
B-spline polynomial descriptors for human activity recognition
A. Oikonomopoulos, M. Pantic, I. Patras. Proceedings of IEEE Int'l Conf. Computer Vision and Pattern Recognition (CVPR-W'08). Anchorage, Alaska, USA, 3: pp. 1 - 6, June 2008.
Bibtex reference [hide]@inproceedings{Oikonomopoulos2008bpdfh,
author = {A. Oikonomopoulos and M. Pantic and I. Patras},
pages = {1--6},
address = {Anchorage, Alaska, USA},
booktitle = {Proceedings of IEEE Int'l Conf. Computer Vision and Pattern Recognition (CVPR-W'08)},
month = {June},
title = {B-spline polynomial descriptors for human activity recognition},
volume = {3},
year = {2008},
}Endnote reference [hide]%0 Conference Proceedings
%T B-spline polynomial descriptors for human activity recognition
%A Oikonomopoulos, A.
%A Pantic, M.
%A Patras, I.
%B Proceedings of IEEE Int?l Conf. Computer Vision and Pattern Recognition (CVPR-W?08)
%D 2008
%8 June
%V 3
%C Anchorage, Alaska, USA
%F Oikonomopoulos2008bpdfh
%P 1-6