Datasets
- CVPR 2023: 5th Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW)
- ECCV 2022: 4th Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW)
- CVPR 2022: 3rd Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW)
- ICCV 2021: 2nd Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW)
- Synthesizing Coupled 3D Face Modalities by TBGAN
- Face Bio-metrics under COVID (Masked Face Recognition Challenge & Workshop ICCV 2021)
- First Affect-in-the-Wild Challenge
- FG-2020 Competition: Affective Behavior Analysis in-the-wild (ABAW)
- Aff-Wild2 database
- First Faces in-the-wild Workshop-Challenge
- In-The-Wild 3D Morphable Models: Code and Data
- Sound of Pixels
- Lightweight Face Recognition Challenge & Workshop (ICCV 2019)
- Audiovisual Database of Normal-Whispered-Silent Speech
- Deformable Models of Ears in-the-wild for Alignment and Recognition
- 300 Videos in the Wild (300-VW) Challenge & Workshop (ICCV 2015)
- 1st 3D Face Tracking in-the-wild Competition
- The Fabrics Dataset
- The Mobiface Dataset
- Large Scale Facial Model (LSFM)
- AgeDB
- AFEW-VA Database for Valence and Arousal Estimation In-The-Wild
- The CONFER Database
- Special Issue on Behavior Analysis "in-the-wild"
- Body Pose Annotations Correction (CVPR 2016)
- KANFace
- MeDigital
- FG-2020 Workshop "Affect Recognition in-the-wild: Uni/Multi-Modal Analysis & VA-AU-Expression Challenges"
- 4DFAB: A Large Scale 4D Face Database for Expression Analysis and Biometric Applications
- Affect "in-the-wild" Workshop
- 2nd Facial Landmark Localisation Competition - The Menpo BenchMark
- Facial Expression Recognition and Analysis Challenge 2015
- The SEWA Database
- 300 Faces In-The-Wild Challenge (300-W), IMAVIS 2014
- Mimic Me
- MAHNOB-HCI-Tagging database
- 300 Faces In-the-Wild Challenge (300-W), ICCV 2013
- MAHNOB Laughter database
- MAHNOB MHI-Mimicry database
- Facial point annotations
- MMI Facial expression database
- SEMAINE database
- iBugMask: Face Parsing in the Wild (ImaVis 2021)
- iBUG Eye Segmentation Dataset
Code
- Valence/Arousal Online Annotation Tool
- The Menpo Project
- The Dynamic Ordinal Classification (DOC) Toolbox
- Gauss-Newton Deformable Part Models for Face Alignment in-the-Wild (CVPR 2014)
- Robust and Efficient Parametric Face/Object Alignment (2011)
- Discriminative Response Map Fitting (DRMF 2013)
- End-to-End Lipreading
- DS-GPLVM (TIP 2015)
- Subspace Learning from Image Gradient Orientations (2011)
- Discriminant Incoherent Component Analysis (IEEE-TIP 2016)
- AOMs Generic Face Alignment (2012)
- Fitting AAMs in-the-Wild (ICCV 2013)
- Salient Point Detector (2006/2008)
- Facial point detector (2010/2013)
- Chehra Face Tracker (CVPR 2014)
- Empirical Analysis Of Cascade Deformable Models For Multi-View Face Detection (IMAVIS 2015)
- Continuous-time Prediction of Dimensional Behavior/Affect
- Real-time Face tracking with CUDA (MMSys 2014)
- Facial Point detector (2005/2007)
- Facial tracker (2011)
- Salient Point Detector (2010)
- AU detector (TAUD 2011)
- Action Unit Detector (2016)
- AU detector (LAUD 2010)
- Smile Detectors
- Head Nod Shake Detector (2010/2011)
- Gesture Detector (2011)
- Head Nod Shake Detector and 5 Dimensional Emotion Predictor (2010/2011)
- Gesture Detector (2010)
- HCI^2 Framework
- FROG Facial Tracking Component
- SEMAINE Visual Components (2008/2009)
- SEMAINE Visual Components (2009/2010)
Facial point annotations
Description:
Existing facial databases cover large variations including: different subjects, poses, illumination, occlusions etc. However, the provided annotations appear to have several limitations.
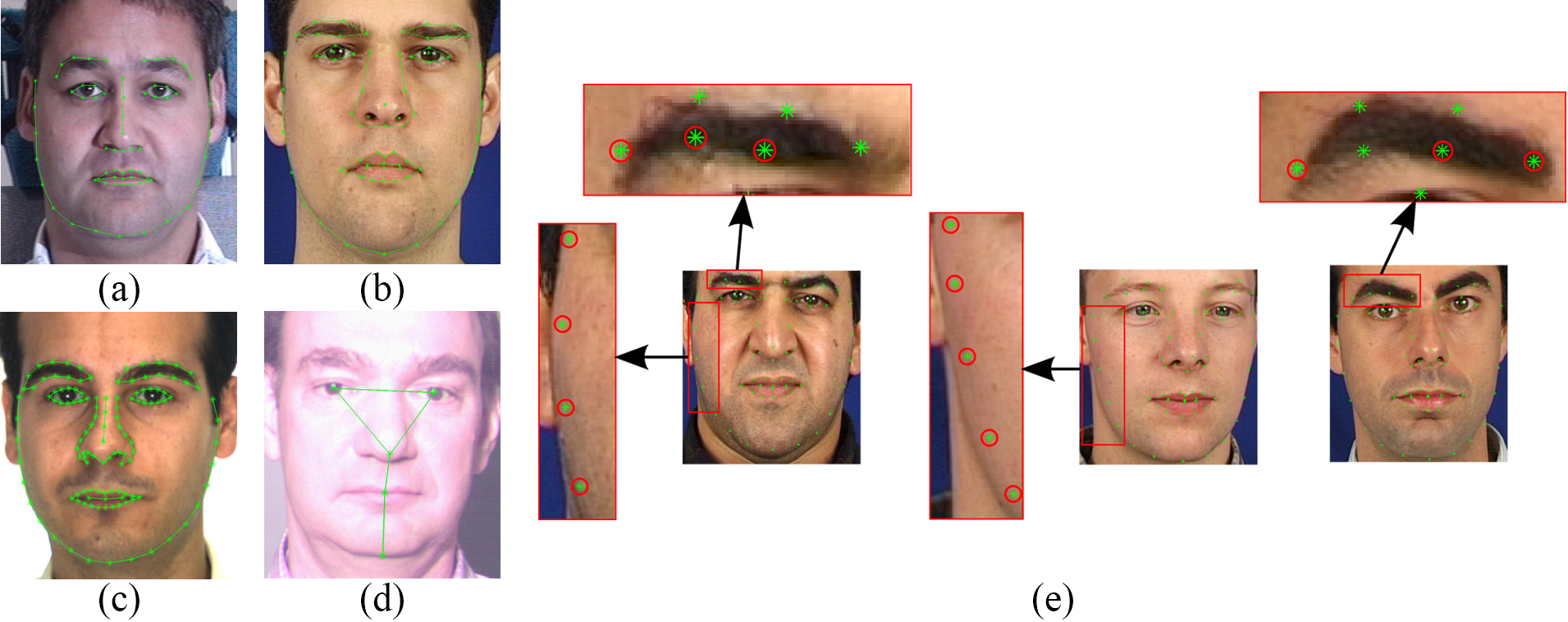
Figure 1: (a)-(d) Annotated images from MultiPIE, XM2VTS, AR, FRGC Ver.2 databases, and (e) examples from XM2VTS with inaccurate annotations.
- The majority of existing databases provide annotations for a relatively small subset of the overall images.
- The accuracy of provided annotations in some cases is not so good (probably due to human fatigue).
- The annotation model of each database consists of different number of landmarks.
These problems make cross-database experiments and comparisons between different methods almost infeasible. To overcome these difficulties, we propose a semi-automatic annotation methodology for annotating massive face datasets. This is the first attempt to create a tool suitable for annotating massive facial databases.
All the annotations are provided for research purposes ONLY (NO commercial products).

Figure 2: The 68 points mark-up used for our annotations.
Download:
We employed our tool for creating annotations (following the Multi-PIE 68 points mark-up, please see Fig. 2) for the following databases:
- 300-W [part1][part2][part3][part4]
Please note that the database is simply split into 4 smaller parts for easier download. In order to create the database you have to unzip part1 (i.e., 300w.zip.001) using a file archiver (e.g., 7zip). - XM2VTS
- FRGC Ver.2
- LFPW
- HELEN
- AFW
- IBUG
References:
Please cite as:
-
C. Sagonas, E. Antonakos, G, Tzimiropoulos, S. Zafeiriou, M. Pantic. 300 faces In-the-wild challenge: Database and results. Image and Vision Computing (IMAVIS), Special Issue on Facial Landmark Localisation "In-The-Wild". 2016.
-
C. Sagonas, G. Tzimiropoulos, S. Zafeiriou, M. Pantic. A semi-automatic methodology for facial landmark annotation. Proceedings of IEEE Int’l Conf. Computer Vision and Pattern Recognition (CVPR-W), 5th Workshop on Analysis and Modeling of Faces and Gestures (AMFG 2013). Oregon, USA, June 2013.
-
C. Sagonas, G. Tzimiropoulos, S. Zafeiriou, M. Pantic. 300 Faces in-the-Wild Challenge: The first facial landmark localization Challenge. Proceedings of IEEE Int’l Conf. on Computer Vision (ICCV-W), 300 Faces in-the-Wild Challenge (300-W). Sydney, Australia, December 2013.
Contact:
Christos Sagonas - c.sagonas@imperial.ac.uk / Stefanos Zafeiriou - s.zafeiriou@imperial.ac.uk