Datasets
- CVPR 2023: 5th Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW)
- ECCV 2022: 4th Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW)
- CVPR 2022: 3rd Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW)
- ICCV 2021: 2nd Workshop and Competition on Affective Behavior Analysis in-the-wild (ABAW)
- Synthesizing Coupled 3D Face Modalities by TBGAN
- Face Bio-metrics under COVID (Masked Face Recognition Challenge & Workshop ICCV 2021)
- First Affect-in-the-Wild Challenge
- FG-2020 Competition: Affective Behavior Analysis in-the-wild (ABAW)
- Aff-Wild2 database
- First Faces in-the-wild Workshop-Challenge
- In-The-Wild 3D Morphable Models: Code and Data
- Sound of Pixels
- Lightweight Face Recognition Challenge & Workshop (ICCV 2019)
- Audiovisual Database of Normal-Whispered-Silent Speech
- Deformable Models of Ears in-the-wild for Alignment and Recognition
- 300 Videos in the Wild (300-VW) Challenge & Workshop (ICCV 2015)
- 1st 3D Face Tracking in-the-wild Competition
- The Fabrics Dataset
- The Mobiface Dataset
- Large Scale Facial Model (LSFM)
- AgeDB
- AFEW-VA Database for Valence and Arousal Estimation In-The-Wild
- The CONFER Database
- Special Issue on Behavior Analysis "in-the-wild"
- Body Pose Annotations Correction (CVPR 2016)
- KANFace
- MeDigital
- FG-2020 Workshop "Affect Recognition in-the-wild: Uni/Multi-Modal Analysis & VA-AU-Expression Challenges"
- 4DFAB: A Large Scale 4D Face Database for Expression Analysis and Biometric Applications
- Affect "in-the-wild" Workshop
- 2nd Facial Landmark Localisation Competition - The Menpo BenchMark
- Facial Expression Recognition and Analysis Challenge 2015
- The SEWA Database
- 300 Faces In-The-Wild Challenge (300-W), IMAVIS 2014
- Mimic Me
- MAHNOB-HCI-Tagging database
- 300 Faces In-the-Wild Challenge (300-W), ICCV 2013
- MAHNOB Laughter database
- MAHNOB MHI-Mimicry database
- Facial point annotations
- MMI Facial expression database
- SEMAINE database
- iBugMask: Face Parsing in the Wild (ImaVis 2021)
- iBUG Eye Segmentation Dataset
Code
- Valence/Arousal Online Annotation Tool
- The Menpo Project
- The Dynamic Ordinal Classification (DOC) Toolbox
- Gauss-Newton Deformable Part Models for Face Alignment in-the-Wild (CVPR 2014)
- Robust and Efficient Parametric Face/Object Alignment (2011)
- Discriminative Response Map Fitting (DRMF 2013)
- End-to-End Lipreading
- DS-GPLVM (TIP 2015)
- Subspace Learning from Image Gradient Orientations (2011)
- Discriminant Incoherent Component Analysis (IEEE-TIP 2016)
- AOMs Generic Face Alignment (2012)
- Fitting AAMs in-the-Wild (ICCV 2013)
- Salient Point Detector (2006/2008)
- Facial point detector (2010/2013)
- Chehra Face Tracker (CVPR 2014)
- Empirical Analysis Of Cascade Deformable Models For Multi-View Face Detection (IMAVIS 2015)
- Continuous-time Prediction of Dimensional Behavior/Affect
- Real-time Face tracking with CUDA (MMSys 2014)
- Facial Point detector (2005/2007)
- Facial tracker (2011)
- Salient Point Detector (2010)
- AU detector (TAUD 2011)
- Action Unit Detector (2016)
- AU detector (LAUD 2010)
- Smile Detectors
- Head Nod Shake Detector (2010/2011)
- Gesture Detector (2011)
- Head Nod Shake Detector and 5 Dimensional Emotion Predictor (2010/2011)
- Gesture Detector (2010)
- HCI^2 Framework
- FROG Facial Tracking Component
- SEMAINE Visual Components (2008/2009)
- SEMAINE Visual Components (2009/2010)
300 Faces In-the-Wild Challenge (300-W), ICCV 2013
Latest News!
- The 300-W dataset has been released and can be downloaded from [part1][part2][part3][part4].
Please note that the database is simply split into 4 smaller parts for easier download. In order to create the database you have to unzip part1 (i.e., 300w.zip.001) using a file archiver (e.g., 7zip). - The data are provided for research purposes only. Commercial use (i.e., use in training commercial algorithms) is not allowed.
- If you use the above dataset please cite the following papers:
-
C. Sagonas, E. Antonakos, G, Tzimiropoulos, S. Zafeiriou, M. Pantic. 300 faces In-the-wild challenge: Database and results. Image and Vision Computing (IMAVIS), Special Issue on Facial Landmark Localisation "In-The-Wild". 2016.
-
C. Sagonas, G. Tzimiropoulos, S. Zafeiriou, M. Pantic. 300 Faces in-the-Wild Challenge: The first facial landmark localization Challenge. Proceedings of IEEE Int’l Conf. on Computer Vision (ICCV-W), 300 Faces in-the-Wild Challenge (300-W). Sydney, Australia, December 2013.
-
C. Sagonas, G. Tzimiropoulos, S. Zafeiriou, M. Pantic. A semi-automatic methodology for facial landmark annotation. Proceedings of IEEE Int’l Conf. Computer Vision and Pattern Recognition (CVPR-W), 5th Workshop on Analysis and Modeling of Faces and Gestures (AMFG 2013). Oregon, USA, June 2013.
-
- Scripts in Matlab, Python and data to generate the results of both versions of the 300W Challenge (ICCV 2013, IMAVIS 2015) in the form of Cumulative Error Distribution (CED) curve can be downloaded from here.
- Second version of the 300 Faces In-the-Wild Challenge announced for a special issue in Elsevier Image and Vision Computing Journal!! Please see here for more details about 300-W 2014!
- A call for papers for a new competition in a journal will be shortly announced. Please keep checking the site for the call. In this special issue, we will run the competition in a similar manner that we did with the competition 300-W.
- Workshop was held on December 7th! Please check the Results session for more information about participants, winners and results!
- The testing database will be released as soon as the IMAVIS papers of the second conduct of the competition (300-W IMAVIS) get accepted. In the meantime, if you wish to compare with the results of this conduct of the competition, feel free to send us your binary code (300faces.challenge@gmail.com) and we will send you back the final results.
300-W
The first Automatic Facial Landmark Detection in-the-Wild Challenge (300-W 2013) to be held in conjunction with International Conference on Computer Vision 2013, Sydney, Australia.
Organisers
Georgios Tzimiropoulos, University of Lincoln, UK
Stefanos Zafeiriou, Imperial College London, UK
Maja Pantic, Imperial College London, UK
Scope
Automatic facial landmark detection is a longstanding problem in computer vision, and 300-W Challenge is the first event of its kind organized exclusively to benchmark the efforts in the field. The particular focus is on facial landmark detection in real-world datasets of facial images captured in-the-wild. The results of the Challenge will be presented at the 300-W Faces in-the-Wild Workshop to be held in conjunction with ICCV 2013.
A special issue of Image and Vision Computing Journal will present the best performing methods and summarize the results of the Challenge.
The 300-W Challenge
Landmark annotations (following the Multi-PIE [1] 68 points mark-up, please see Fig. 1) for four popular data sets are available from here. All participants in the Challenge will be able to train their algorithms using these data. Performance evaluation will be carried out on 300-W test set, using the same Multi-PIE mark-up, and the same face-bounding box initialization.
 |
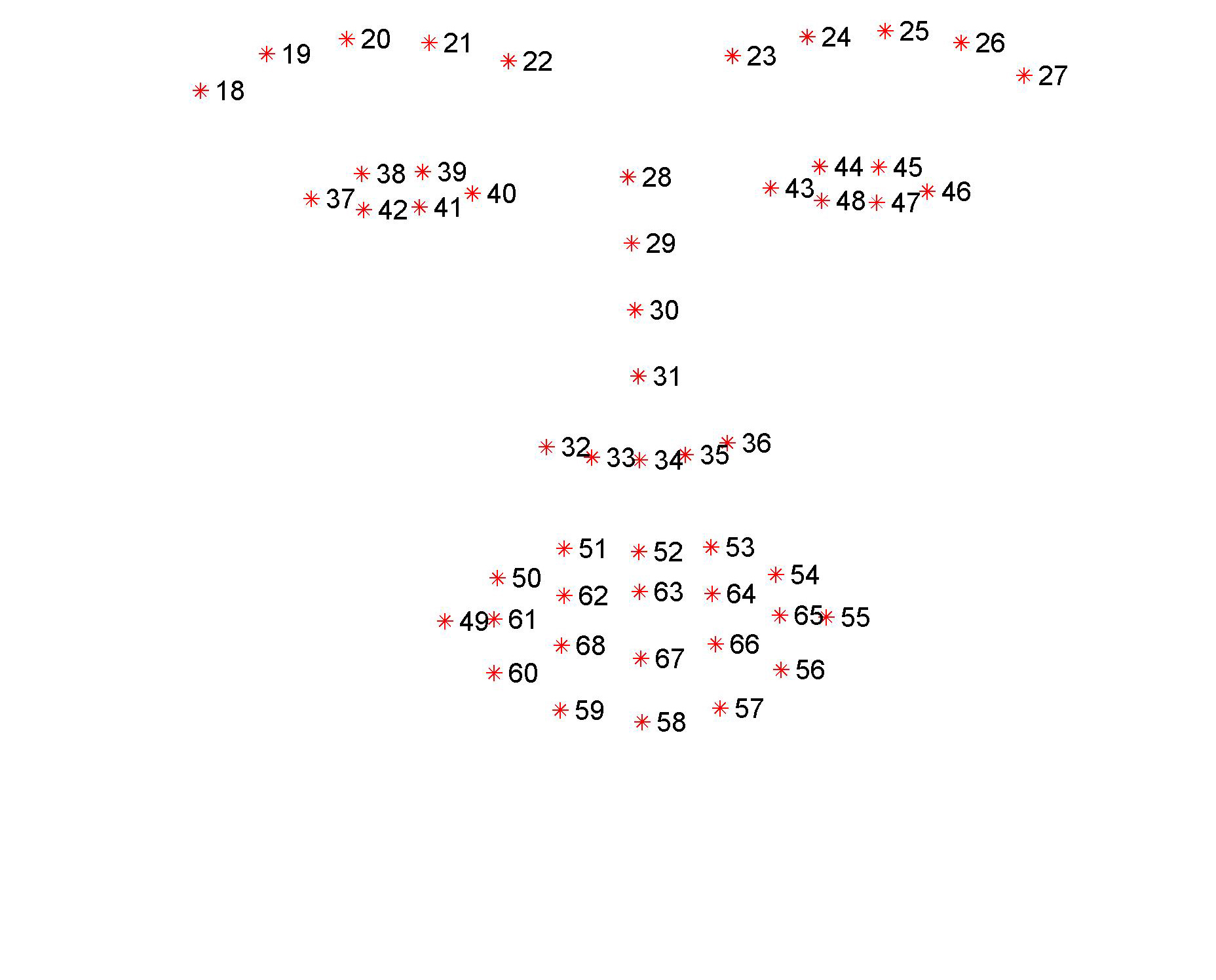 |
Figure 1: The 68 and 51 points mark-up used for our annotations.
Training
The datasets LFPW [2], AFW [3], HELEN [4], and XM2VTS [5] have been re-annotated using the mark-up of Fig 1. We provide additional annotations for another 135 images in difficult poses and expressions (IBUG training set). Annotations have the same name as the corresponding images. For LFPW, AFW, HELEN, and IBUG datasets we also provide the images. The remaining image databases can be downloaded from the authors’ websites. All annotations can be downloaded from here.
Participants are strongly encouraged to train their algorithms using these training data. Should you use any of the provided annotations please cite [6] and the paper presenting the corresponding database.
Please note that the re-annotated data for this challenge are saved in the matlab convention of 1 being
the first index, i.e. the coordinates of the top left pixel in an image are x=1, y=1.
Testing
Participants will have their algorithms tested on a newly collected data set with 2x300 (300 indoor and 300 outdoor) face images collected in the wild (300-W test set). Sample images are shown in Fig 2 and Fig 3.
 |
 |
Figure 2: Outdoor. |
Figure 3: Indoor. |
300-W test set is aimed to test the ability of current systems to handle unseen subjects, independently of variations in pose, expression, illumination, background, occlusion, and image quality.
Participants should send binaries with their trained algorithms to the organisers, who will run each algorithm on the 300-W test set using the same bounding box initialization. This bounding box is provided by our in-house face detector. The face region that our detector was trained on is defined by the bounding box as computed by the landmark annotations (please see Fig. 4).
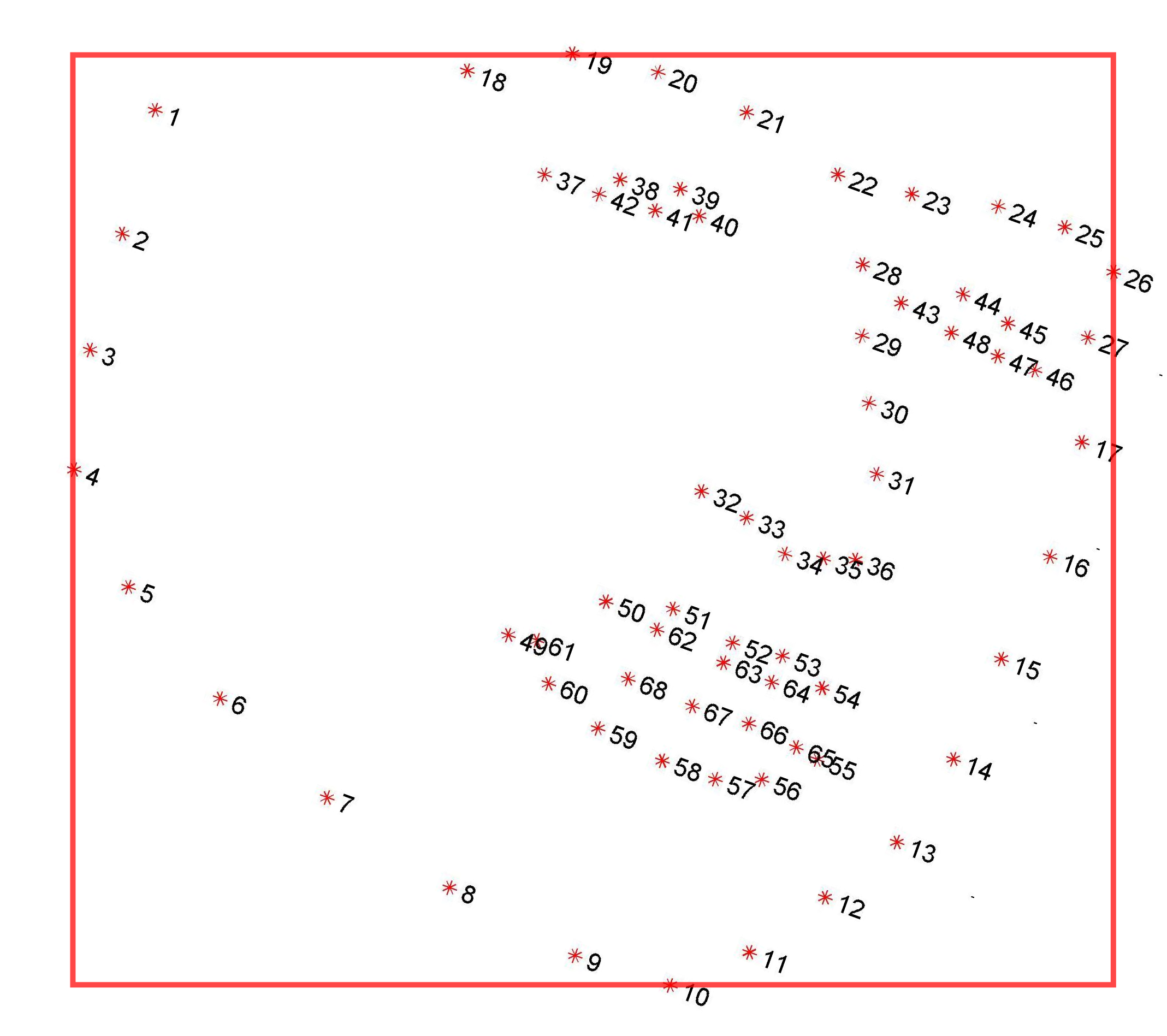
Figure 4: Face region (bounding box) that our face detector was trained on.
Examples of bounding box initialisations along with the ground-truth bounding boxes are show in Fig. 5. We provide the bounding box initialisations, as produced by our in-house detector, for each database of the training procedure. Additionaly the bounding boxes of the ground truth are given.
 |
 |
Figure 5: Examples of bounding box initialisations for images from the test set of LFPW.
Participants should expect that initialisations for the 300-W test set are of similar accuracy.
Each binary should accept two inputs: input image (RGB with .png extension) and the coordinates of the bounding box. Bounding box should be a 4x1 vector [xmin, ymin, xmax, ymax] (please see Fig. 6). The output of the binary should be a 68 x 2 matrix with the detected landmarks. This matrix should be saved in the same format (.pts) and ordering as the one of the provided annotations.

Figure 6: Coordinates of the bounding box (the coordinates of the top left pixel are x=1, y=1).
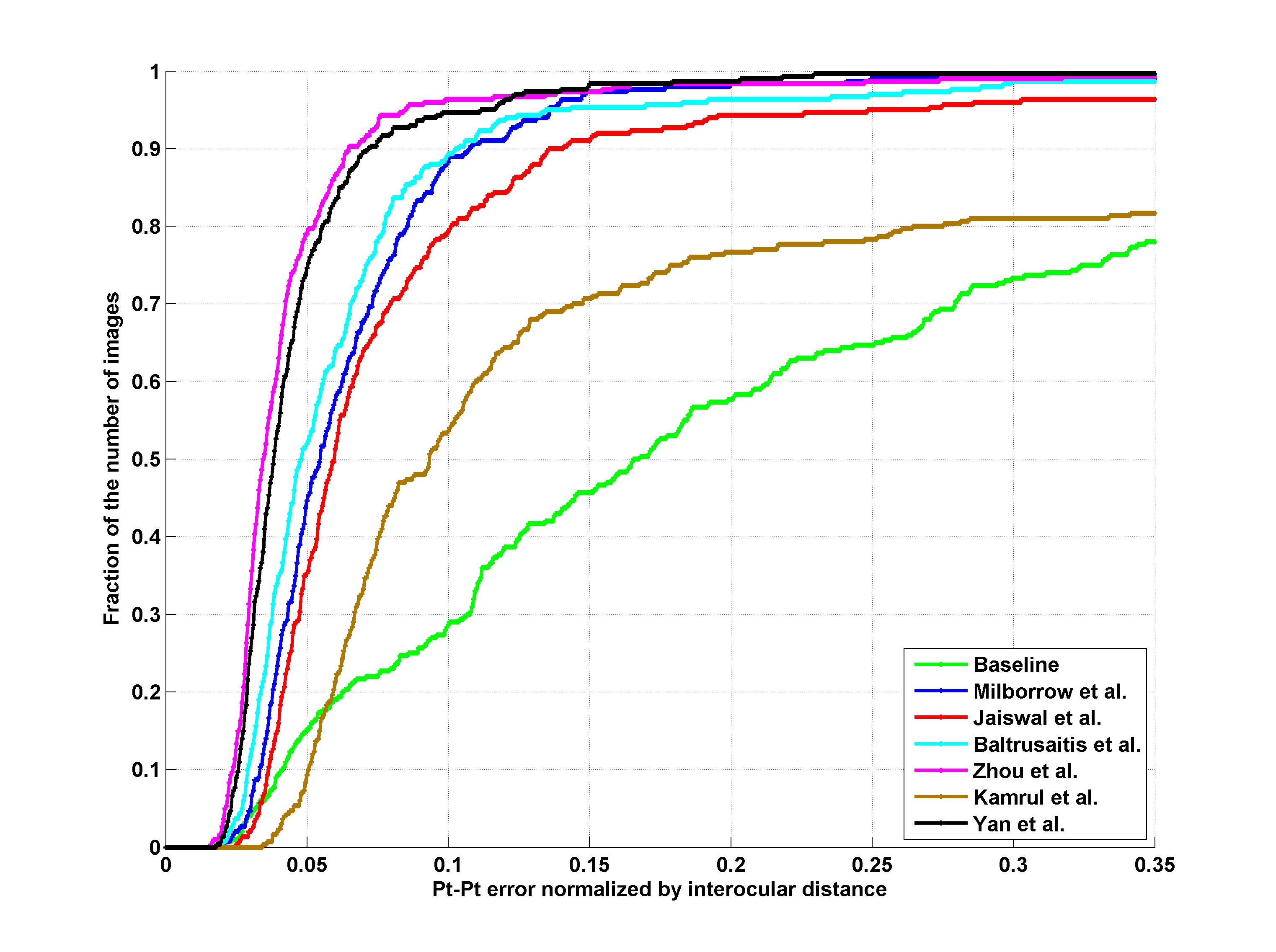
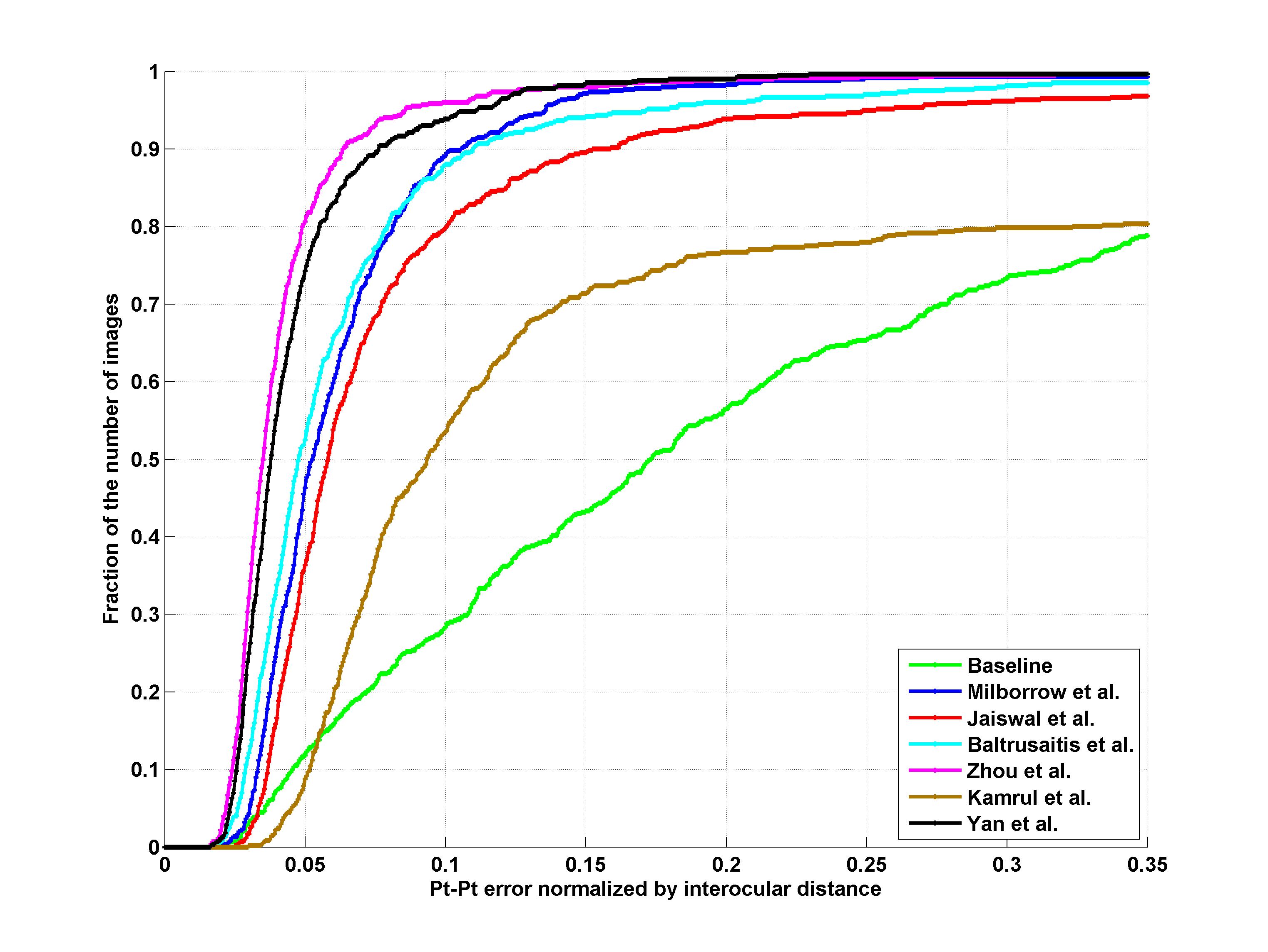
Facial landmark detection performance will be assessed on both the 68 points mark-up of Fig 1 and the 51 points which correspond to the points without border (please see Fig1). The average point-to-point Euclidean error normalized by the inter-ocular distance (measured as the Euclidean distance between the outer corners of the eyes) will be used as the error measure. Matlab code for calculating the error can be downloaded from http://ibug.doc.ic.ac.uk/media/uploads/competitions/compute_error.m. Finally, the cumulative curve corresponding to the percentage of test images for which the error was less than a specific value will be produced. Additionally, fitting times will be recorded. These results will be returned to the participants for inclusion in their papers.
The binaries submitted for the competition will be handled confidentially. They will be used only for the scope of the competition and will be erased after the completion. The binaries should be complied in a 64bit machine and dependencies to publicly available vision repositories (such as Open CV) should be explicitly stated in the document that accompanies the binary
Winners
- J. Yan, Z. Lei, D. Yi, and S. Z. Li. Learn to combine multiple hypotheses for face alignment. (Academia)
- E. Zhou, H. Fan, Z. Cao, Y. Jiang, and Q. Yin. Facial landmark localization with coarse-to-fine convolutional network cascade. (Industry)
Results
Indoor
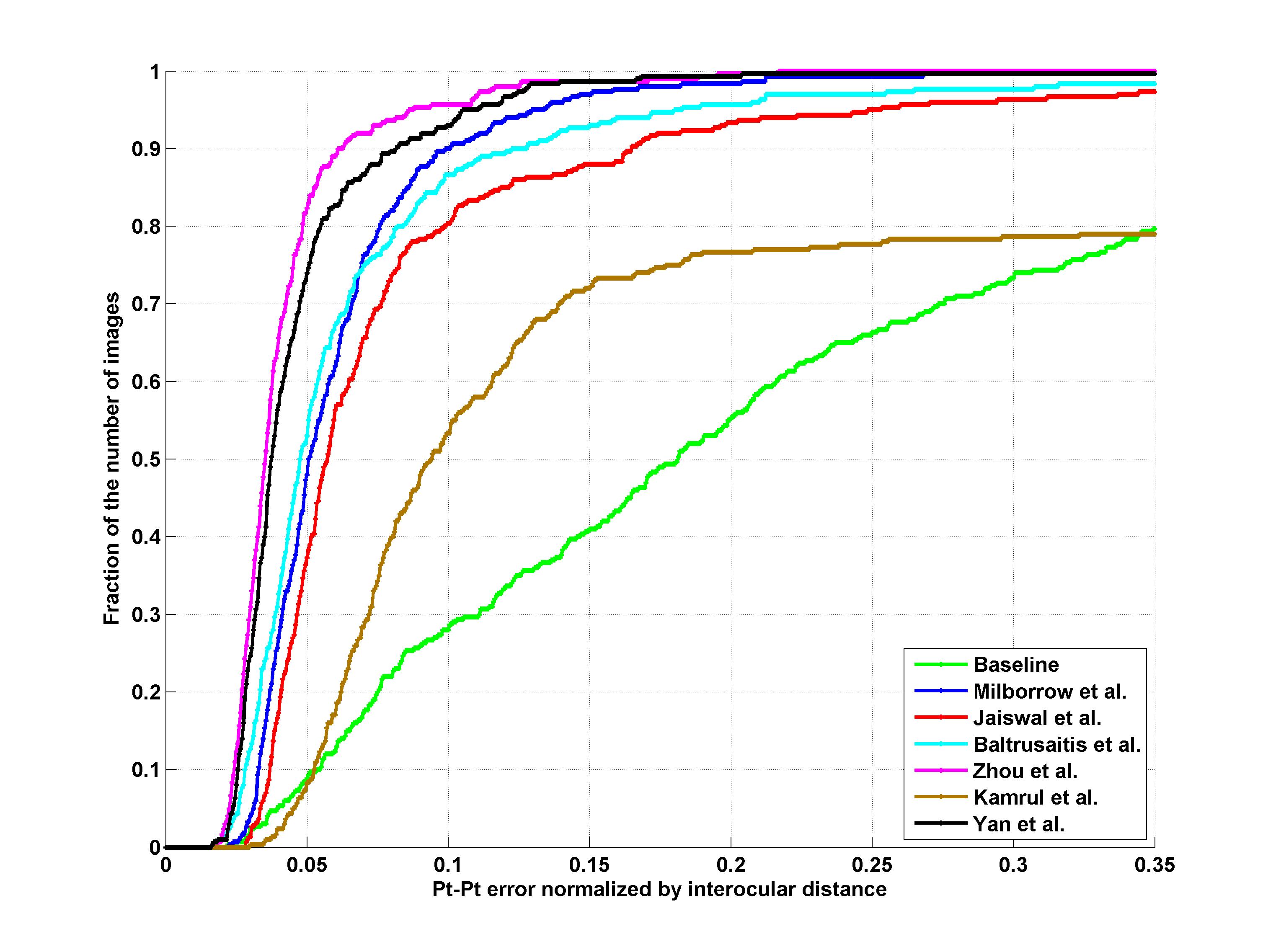 |
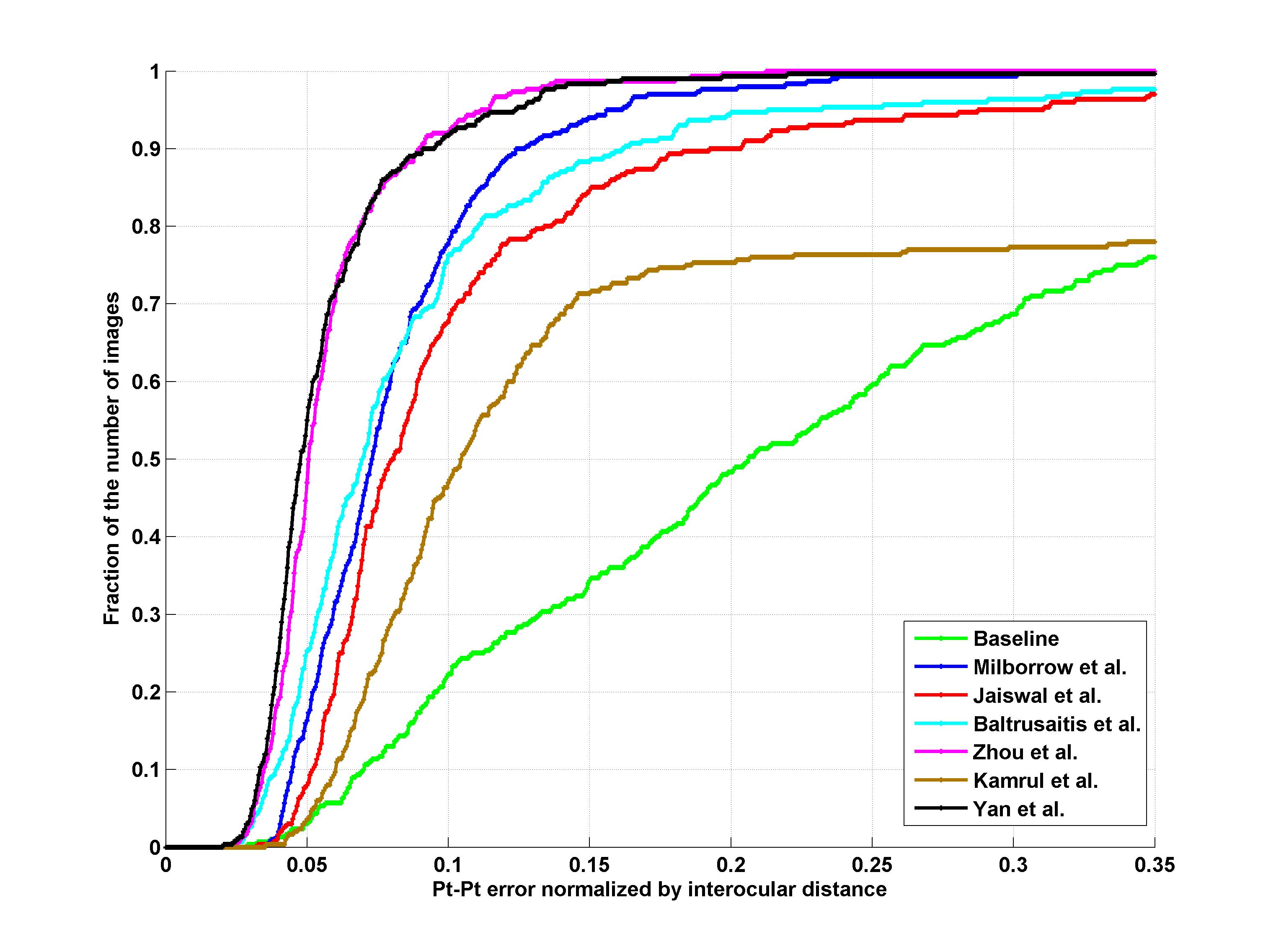 |
| 51 points | 68 points |
Outdoor
 |
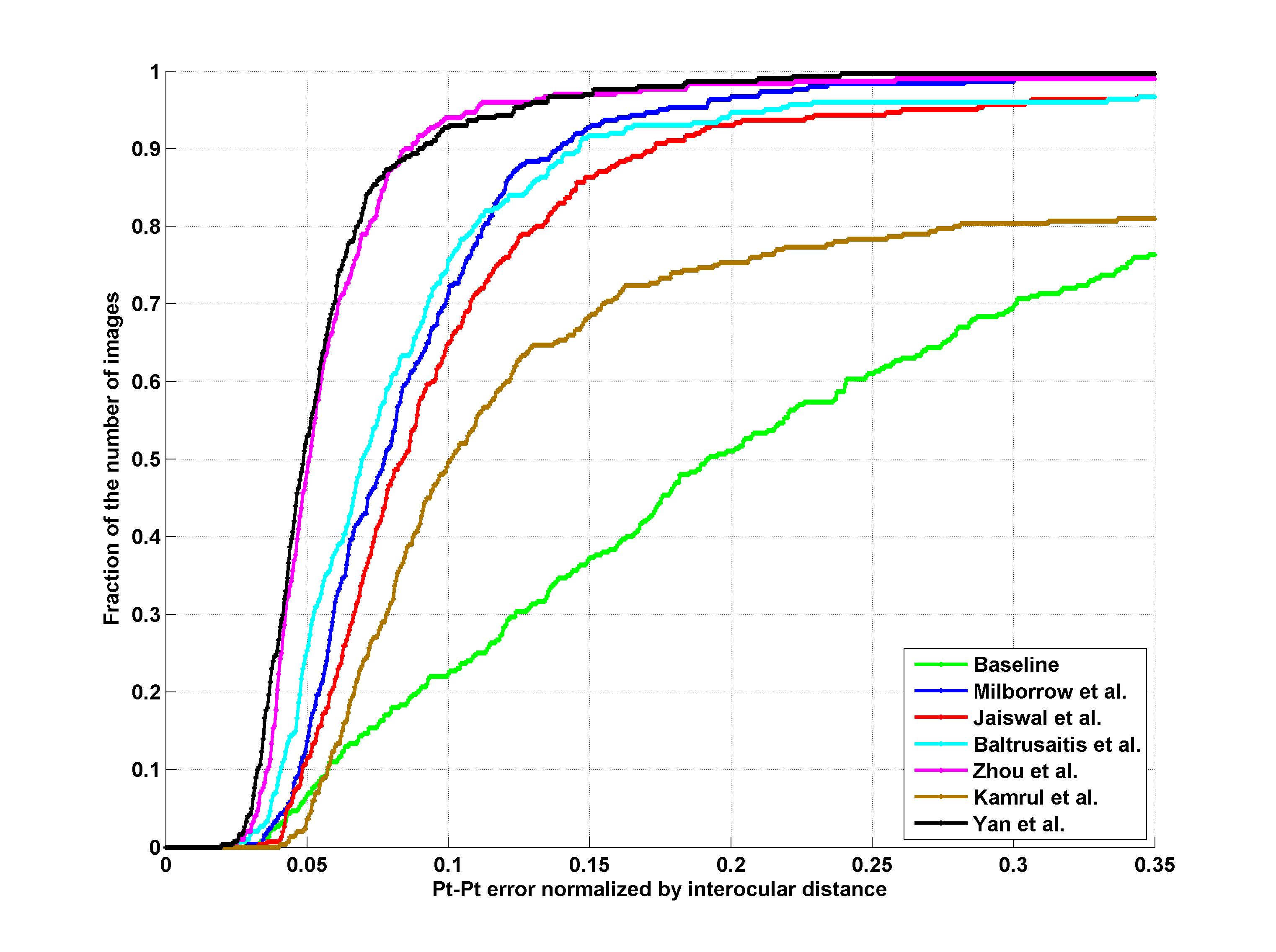 |
| 51 points | 68 points |
Indoor + Outdoor
 |
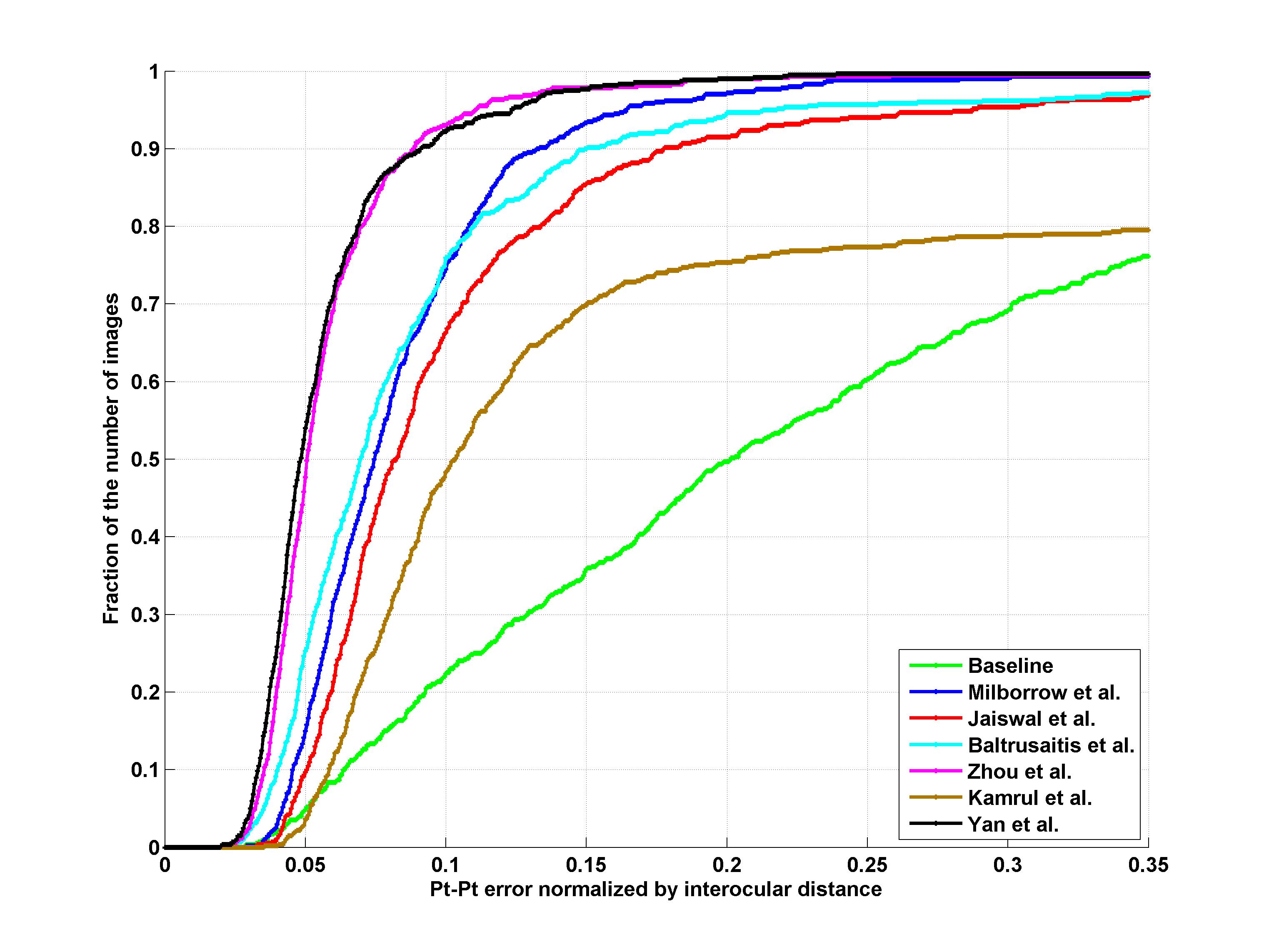 |
| 51 points | 68 points |
Participants
1. S. Milborrow, T. Bishop, and F. Nicolls. Multiview active shape models with sift descriptors for the 300-w face landmark challenge.
2. S. Jaiswal, T. Almaev, and M. Valstar. Guided unsupervised learning of mode specific models for facial point detection in the wild.
3. T. Baltrusaitis, L.-P. Morency, and P. Robinson. Constrained local neural fields for robust facial landmark detection in the wild.
4. E. Zhou, H. Fan, Z. Cao, Y. Jiang, and Q. Yin. Facial landmark localization with coarse-to-fine convolutional network cascade.
5. K. Hasan Md., S. Moalem, and C. Pal. Localizing facial keypoints with global descriptor search, neighbour alignment and locally linear models.
6. J. Yan, Z. Lei, D. Yi, and S. Z. Li. Learn to combine multiple hypotheses for face alignment.
Submission Information
Challenge participants should submit a paper to the 300-W Workshop, which summarizes the methodology and the achieved performance of their algorithm. Submissions should adhere to the main ICCV 2013 proceedings style, and have a maximum length of 8 pages and will be charged a fee if $200, regardless of length. The workshop papers will be published in the ICCV 2013 proceedings. Please sign up in the submissions system to submit your paper.
Important Dates
- Binaries submission deadline: September 7, 2013
- Paper submission deadline: September 15, 2013 September 23, 2013 (Extended deadline)
- Author Notification: October 7, 2013
- Camera-Ready Papers: October 10, 2013
Contact
Dr. Georgios Tzimiropoulos
gtzimiropoulos@lincoln.ac.uk, gt204@imperial.ac.uk
Intelligent Behaviour Understanding Group (iBUG)
References
[1] R. Gross, I. Matthews, J. Cohn, T. Kanade, and S. Baker.Multi-pie. Image and Vision Computing, 28(5):807–813, 2010.
[2] Belhumeur, P., Jacobs, D., Kriegman, D., Kumar, N.. ‘Localizing parts of faces using a consensus of exemplars’. In Computer Vision and Pattern Recognition, CVPR. (2011).
[3] X. Zhu, D. Ramanan. ‘Face detection, pose estimation and landmark localization in the wild’, Computer Vision and Pattern Recognition (CVPR) Providence, Rhode Island, June 2012.
[4] Vuong Le, Jonathan Brandt, Zhe Lin, Lubomir Boudev, Thomas S. Huang. ‘Interactive Facial Feature Localization’, ECCV2012.
[5] Messer, K., Matas, J., Kittler, J., Luettin, J., Maitre, G. ‘Xm2vtsdb: The ex- tended m2vts database’. In: 2nd international conference on audio and video-based biometric person authentication. Volume 964. (1999).
[6] C. Sagonas, G. Tzimiropoulos, S. Zafeiriou and Maja Pantic. ‘A semi-automatic methodology for facial landmark annotation’, IEEE Int’l Conf. Computer Vision and Pattern Recognition (CVPR-W’13), 5th Workshop on Analysis and Modeling of Faces and Gestures (AMFG2013). Portland Oregon, USA, June 2013 (accepted for publication).
Program Committee
- Fernando De la Torre, Carnegie Mellon University (USA)
- Roland Goecke, University of Canberra (AUS)
- Mircea C. Ionita, Daon (UK)
- Qiang Ji, Rensselaer Polytechnic Institute (USA)
- Ioannis A. Kakadiaris, University of Houston (USA)
- Simon Lucey, CSIRO ICT Centre (AUS)
- Brais Martinez, Imperial College London (UK)
- Louis-Philippe Morency, USC Los Angeles (USA)
- Ioannis (Yiannis) Patras, Queen Mary University (UK)
- Jason Saragih, Freelance, (AUS)
- Gabor Szirtes, RealEyes (UK / Hungary)
- Michel Valstar, University of Nottingham (UK)
- Lijun Yin, Binghampton University (USA)
Sponsors